.png)
Artificial intelligence technology has evolved from chatbots to the use of AI agents and automation. Previously used only as chatbots with functions like knowledge-based search, AI technology is now being used with various tools for automation, complete automation of repetitive tasks, and especially by enterprises to save time and labor. This shift requires AI agents to take precautions against a new type of attack: prompt injection attacks, which have ranked as the #1 vulnerability in the OWASP Top 10 for LLM Applications since the list was first published and remains at the top in the 2025 edition. Let’s discover ways to prevent prompt injection attacks.
TL; DR
As AI agents evolve from chatbots into autonomous systems that handle real tools and workflows, they become prime targets for prompt injection attacks, textual tricks that manipulate models into leaking data or making harmful decisions. Defending against them means layering controls: sanitize inputs, restrict privileges, keep humans in the loop for critical actions, filter outputs, and monitor for anomalies in real time. Combine that with tight tool authorization, regulatory compliance, and detailed audit logs. If you need an enterprise-ready platform that bundles AI automation with SOC 2, ISO 27001, and GDPR safeguards, TextCortex offers a secure infrastructure built for exactly that.
What is Prompt Injection?
Prompt injection is a textual attack method used by attackers to manipulate the behavior and output of a large language model. Prompt injection attacks carry risks such as data theft, unauthorized access, harmful content generation, guideline violations, and wrong decision-making. It involves introducing specific inputs and altering the model's output to manipulate the model. Prompt injection has two versions: direct and indirect.
Direct Prompt Injection
Direct prompt injection occurs on platforms where the attacker directly interacts with the large language model. For example, chat boxes that allow interaction with the large language model are an ideal attack method for direct prompt injection. Because this attack method is direct, it is relatively easy to block and counter.
Indirect Prompt Injection
Indirect prompt injection occurs in scenarios where large language models (LLMs) can interact with external resources. For example, when LLMs interact with websites or databases, or grant file upload permissions, there is a risk of indirect prompt injection. This threat is growing rapidly: Google’s scans of web content found a 32% increase in malicious content designed for indirect prompt injection between November 2025 and February 2026, according to a Palo Alto Networks analysis.
How to Prevent Prompt Injection?
There are several measures you can take to prevent prompt injection. Let's discover these measures step by step.
1. Input Sanitization
The first method of prompt injection prevention is to configure which inputs your large language model will accept and which will be flagged as malicious and not processed. For example, you should teach your model not to process inputs that require it to ignore previous commands and precautions during role-playing. Inputs that use too much punctuation are also risky for breaking the model's behavior. The first measure and first shield you will take is to restrict the behavior that pure input will have on your model.
2. Privilege Minimization
An AI agent should only have access to the information it needs and will use. This way, in any prompt injection situation, the AI agent can avoid causing critical damage. IBM’s 2025 Cost of a Data Breach report found that 97% of organizations that experienced AI-related breaches lacked proper AI access controls, reinforcing that an AI agent you only use to read your emails should not also need access to write and send emails, or to transfer your emails to another document and send them to another medium.
3. Human In Loop
While AI agents can automate most tasks, using them for complete automation is dangerous, especially for critical tasks. Therefore, in critical areas like sending money, issuing invoices, sending emails, and payment processes, you should prevent the AI agent from making the final decision and ensure a human makes the final decision. This way, in a prompt injection attack, the AI agent could submit critical processes to human control before completion.
4.Output Filtering
Prompt injection involves manipulating the output of AI agents or large language models through input. Therefore, you can bypass most prompt injection attacks without damage by filtering the output of the AI agent or large language model.
5. Real-Time Prompt Injection Detection
Specialized classifiers and pattern-matching engines continuously scan incoming inputs and outgoing outputs, identifying risky instructions, potential attacks, and hostile structures. When any prompt injection attack is detected, output generation is blocked. The AI agent’s permissions and actions are restricted, preventing the potential prompt injection attack. This layer of defense is critical: security research shows that 73% of AI systems assessed in security audits are exposed to prompt injection vulnerabilities, yet current detection methods catch only 23% of sophisticated attacks without dedicated real-time scanning in place.
6. Behavioral Monitoring and Anomaly Detection
Behavioral monitoring and anomaly detection systems query unusual data sources; they detect any abnormal prompts and send them to the user. This allows you to simultaneously monitor your AI agent or Large Language model and directly detect potential prompt injection attacks, such as AI agents suddenly attempting to make 500 API calls.
7. Tool-Use Authorization
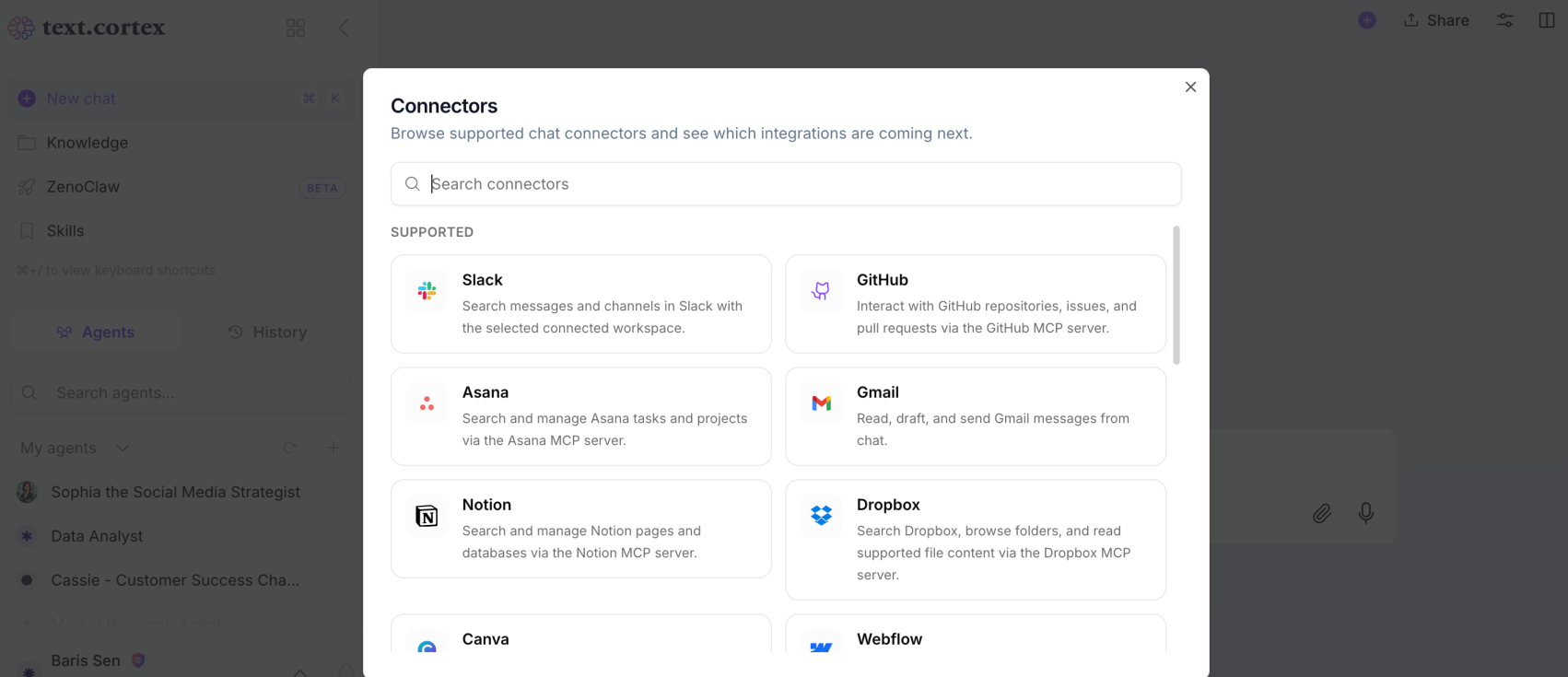
AI agents are gaining access to more and more third-party applications and tools every day. This makes improperly authorized tool usage a perfect target for prompt injection attacks. By authorizing which tools can be used by whom and under what parameters, you can protect your AI agent from prompt injection attacks and prevent it from becoming a data-leaking bot. If your AI agent platform allows you to authorize members and manage their permissions, you are one step ahead.
8. Regulatory Alignment
Global regulations ensure that AI agents are protected from more than just generating malicious content, and AI Agent Prompt Injection attacks are one of them. Notably, the NIST AI agent security framework mandates human-in-the-loop review for operations involving personal data, transactions exceeding defined thresholds, irreversible actions such as data deletion, and any access to new external systems. You need to ensure that the AI agent or AI agent platform you are using complies with global regulations and is certified. This ensures that your AI agent operates more securely and is more resistant to prompt injection attacks.

9. Auditing and Logging
Ensure you audit and record every action and decision of the AI agent. This allows you to observe abnormal behavior or identify where the AI agent made a mistake. After any prompt injection attack, auditing and reviewing the logs will help you take precautions against similar attacks.
TextCortex: Safe and Secure AI Agent Infrastructure
If you want your AI agents and the AI models you integrate into your enterprise to be both effective and reliable, TextCortex is the solution for you. TextCortex offers its users both a secure and safe AI experience and access to the latest automation and AI features. Core features offered by TextCortex include:
- AI Agents for Automation
- Knowledge Bases
- Skills
- Browser Extension
- Connectors
- Seamless Integrations
- AI Agent Builder
- Multiple LLM Libraries, including Claude Opus 4.7, GPT-5.5
- Multiple Image Generators
- Web Access
Furthermore, TextCortex offers all these features with state-of-the-art security.
TextCortex AI Security and Safety
TextCortex offers various security measures to protect its users' sensitive data. You can access all of TextCortex's security programs and information via this link. TextCortex's first enterprise AI security offerings are its compliance and certifications. In addition to compliance with EU AI Act regulations and GDPR, TextCortex offers SOC 2 Type I, SOC 2 Type II, and ISO 27001 certifications.
Policies
TextCortex offers policies in four different areas to provide users with a secure and safe AI experience:
- Application Security
- Data Security and Privacy
- Infrastructure Security
- Security Operations

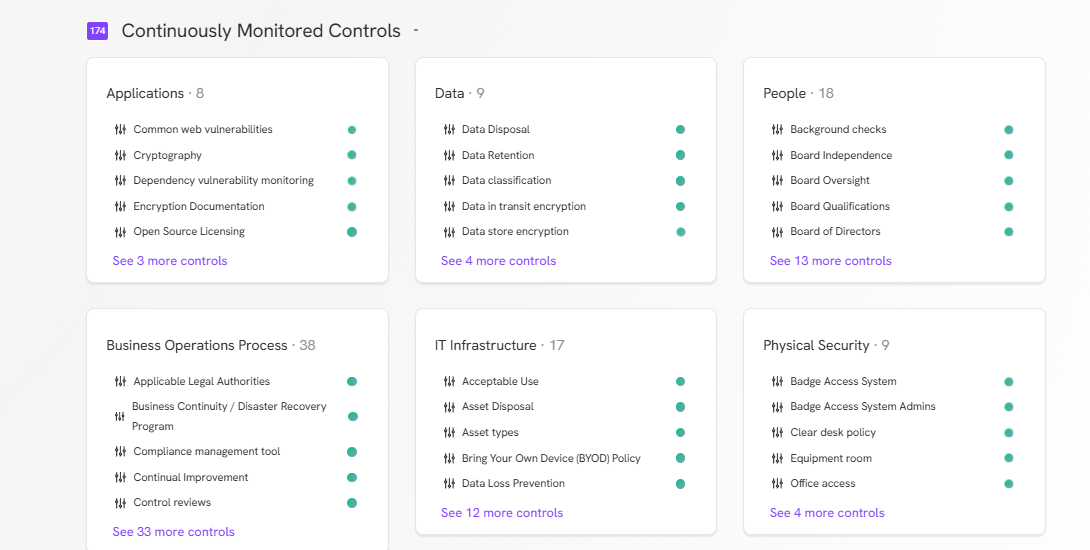
Continuously Monitored Controls
Before integrating TextCortex into your enterprise, you should know that it allows you to continuously monitor a wide range of controls. With TextCortex, you can monitor controls under the following headings:
- Applications
- Data
- People
- Business Operation Process
- IT Infrastructure
- Physical Security
- Cloud Infrastructure
- Identity and Access Control
- Privacy
- Customers
- Monitoring
- Product Delivery Process
- Vendors

Frequently Asked Questions
What exactly is prompt injection, and why should my enterprise care about it?
Prompt injection is when an attacker slips malicious text into an AI agent's input stream to trick the model into ignoring its instructions, leaking data, or taking unauthorized actions. It is not a theoretical risk: Snyk found that 36% of ClawHub skills contain detectable prompt injection, and enterprises are already seeing real CVEs tied to agentic AI.
What is the difference between direct and indirect prompt injection?
Direct prompt injection happens when an attacker types a malicious command straight into a chat interface, trying to override the system prompt right then and there. Indirect prompt injection is sneakier: the attacker hides malicious instructions inside an external resource the agent consumes, like a website, a PDF, or a database entry.
Can input sanitization alone stop prompt injection?
Input sanitization is your first shield, but it is not a fortress on its own. It works by flagging and blocking patterns like role-play prefixes, "ignore previous instructions," or excessive punctuation that tries to break delimiter boundaries. The problem is that attackers constantly find new ways to obfuscate their inputs. Sanitization buys you time and catches the obvious attempts, but it needs to be stacked with privilege limits, output filtering, and monitoring to be truly effective.
Is there a way to detect prompt injection in real time?
Yes. Specialized classifiers and pattern-matching engines can scan both incoming prompts and outgoing responses continuously, looking for adversarial structures like instruction overrides or delimiter breaks. When a threat signature matches, the system can block the request, restrict the agent's permissions, or route the traffic to a safer fallback. Microsoft and other platforms offer prompt shields and AI gateways that act as this real-time control layer.
Do global regulations actually require prompt injection defenses?
Regulations like the EU AI Act, the NIST AI Risk Management Framework, and ISO/IEC 42001 are increasingly requiring transparency, human oversight, and risk management for AI systems. While none of them use the words "prompt injection" verbatim, the requirement to prevent unauthorized manipulation, data leakage, and harmful outputs maps directly to prompt injection mitigation.
.png)
.png)
.png)