%20(51).png)
すでにお気づきかもしれませんが、ChatGPTは非常に基本的なチャットボットで、個人レベルでの会話や特定のニーズに応えることはできません。
しかし、あなたのビジネスのあらゆる側面を理解し、24時間365日休みなく顧客からの問い合わせに対応する高度にインテリジェントなChatGPTチャットボットを想像してみてください。
これは、パーソナライズされたデータでAIチャットボットを訓練し、御社のためのカスタムAIチャットボットを作成することで可能になります。
このエキサイティングな機会を利用して、ウェブサイト訪問者とのコミュニケーション方法を変える可能性のある独自のChatGPTチャットボットを構築するために必要な魅力的なテクニック、ツール、アドバイスを探求し、共有します。
ChatGPTとは?
ChatGPTはOpenAIが開発したAIチャットボットです。自然言語処理と機械学習を活用し、ユーザーの入力から回答を作成する。ユーザーはAIボットとチャットすることで、ChatGPTとの会話をもとに、アウトライン、記事、ストーリー、サマリーを作成することができる。
このAIチャットボットには大きな利点がある-以前の会話を思い出すことができ、次回以降スムーズなエンゲージメントを提供できる。最初の使用はGPT- techに基づいていますが、ChatGPT Agentやその他の機能を利用するには、Plusパッケージ契約が必要です。

特徴
ChatGPTは、過去のチャットを記憶し、ユーザーがフォローアップの質問をすることができるため、質の高い会話体験を提供することができます。さらに、ChatGPTは大量のインターネットデータを使って学習させました。
ChatGPTは、プロンプトに対する応答を生成するだけでなく、任意のプログラミング言語で入力コードや中間コードを作成することができます。そのためには、ChatGPTに必要なプログラミング言語を伝え、必要なコードを記述するだけです。ChatGPTは入力を分析し、指定されたプログラミング言語でコードを生成します。さらに、ChatGPTが生成したコードを、あなたのニーズに合わせて改良したり、短くしたりすることができます。
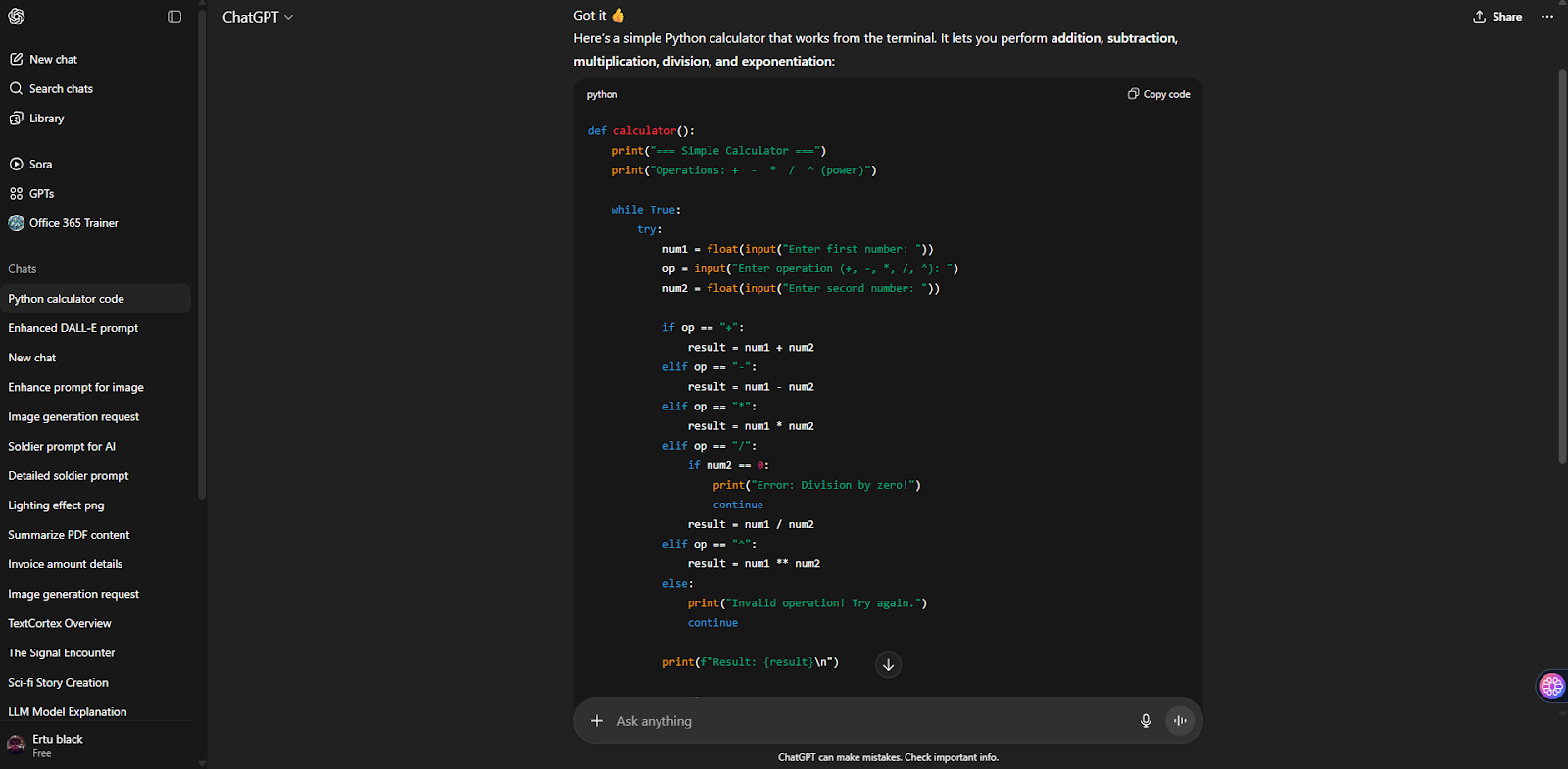
ChatGPTのもう一つの特徴は、あなたのコードブロックのエラーを見つけ、あなたに説明してくれることです。あなたのコードにエラーがあり、それを見つけることができない場合、ChatGPTを使用することができます!では次に、このスマートなチャットボットを自分のデータでどのように学習させるかについて説明します。
自分のデータでChatGPTをトレーニングするには?
1つはプログラミングの専門知識が必要な方法、もう1つはコーディングの経験がなくてもわずか4分で完了する方法だ。
ノーコード・ソリューションに進みたい場合は、こちらをクリックしてください、 ここをクリック.
によるフルコード・ソリューションAPI
始める前に、このセクションではコーディングの経験とPyhtonの幅広い理解が必要であることをお断りしておきます。ノーコードのソリューションをお探しの場合は、こちらをクリックして ください。カスタマイズされたChatGPT AIチャットボットを訓練する前に、コンピュータにソフトウェア環境をセットアップする必要があります。以下はその手順です。
ステップ1:Pythonのインストールとアップグレード
まず第一に、Pythonを公式サイトからダウンロードしてインストールする。 公式ウェブサイト.セットアップ中に "Add Python.exe to PATH "オプションをチェックすることを忘れないこと。次に、PythonライブラリをインストールするためのパッケージマネージャであるPipをアップグレードします。
これは、Windowsではターミナル、macOSではコマンドプロンプトから行うことができます。最後に、OpenAIライブラリ、GPT Index、PDFファイルを解析するためのPyPDF2、PyCryptodomeなど、チャットボットを訓練するために必要不可欠なライブラリをインストールします。これらのライブラリは、あなたの知識ベースに接続し、カスタムAIチャットボットを訓練することができる大規模言語モデル(LLM)を作成するために重要です。
ステップ2:コードエディター(VS Codeなど)をインストールする。
まず、Windows用のNotepad++や、macOSやLinux用のSublime Textのようなコードエディタをダウンロードします。 VSコード.
ステップ 3:API キーとシークレットキーの生成
次に、カスタムナレッジベースを使用するチャットボットをトレーニングして作成するには、OpenAIからAPI キーが必要です。このキーを取得するには、OpenAI でアカウントを作成 するか、既存のアカウントにログインして、プロフィールから "ViewAPI keys" を選択し、"Create new secret key" をクリックして、固有のAPI キーを生成します。この鍵はプレーンテキストファイルに保存し、自分のアカウントにしかアクセスできないため、秘密にしておくことが重要です。さらに、必要に応じて最大5つのAPI キーを作成することができます。

ソフトウェア環境をセットアップし、OpenAIAPI キーを取得したら、いよいよデータを使って自分のAIチャットボットを訓練します。
ステップ4:モデルの選択とナレッジベースの作成
gpt-5 "モデルか "gpt-4.1 "のどちらかを選択することができます。始めに、"docs "という名前のフォルダを作成し、そこにテキスト、PDF、CSV、SQLファイルなどの形式のトレーニング・ドキュメントを追加します。
ステップ5:スクリプトの作成
次に、コードエディターを開き、以下のコードを "app.py" として "docs" フォルダーと同じフォルダーに保存します。コード内の "YourAPI Key "というテキストを、OpenAIから取得したAPI キーに置き換えて、変更を保存してください。
ターミナルでコードを実行してドキュメントを処理し、JSONファイルを作成すると、ローカルURLが生成されます。copy 、このURLをウェブブラウザに貼り付けるだけで、カスタムトレーニングされたChatGPT AIチャットボットにアクセスできます。
これで、チャットボットに質問をして、提供されたデータに基づいて回答を受け取ることができる。
TextCortex によるノーコード・ソリューション - ナレッジベース
TextCortex を使えば、自分のデータを使って人工知能(AI)を簡単にトレーニングできる。さらに、声やスタイルなどのパーソナライズされた入力を追加することで、カスタムペルソナをさらにカスタマイズすることができます。カスタムペルソナは、あなたの想像力に合わせたバーチャルツインやブランド代表を作るのに役立ちます。
視覚学習者の方は、知識ベースを作成し、ご自身のデータでZenoをトレーニングする方法についての短いビデオをご覧ください。
非常にシンプルなステップでそれを実現する方法を説明する前に、実際に使ってみて、あなたのニーズにどれだけの価値を提供できるかを理解してほしい。
カスタムデータでAIをトレーニングするには?- ステップバイステップのクイックガイド
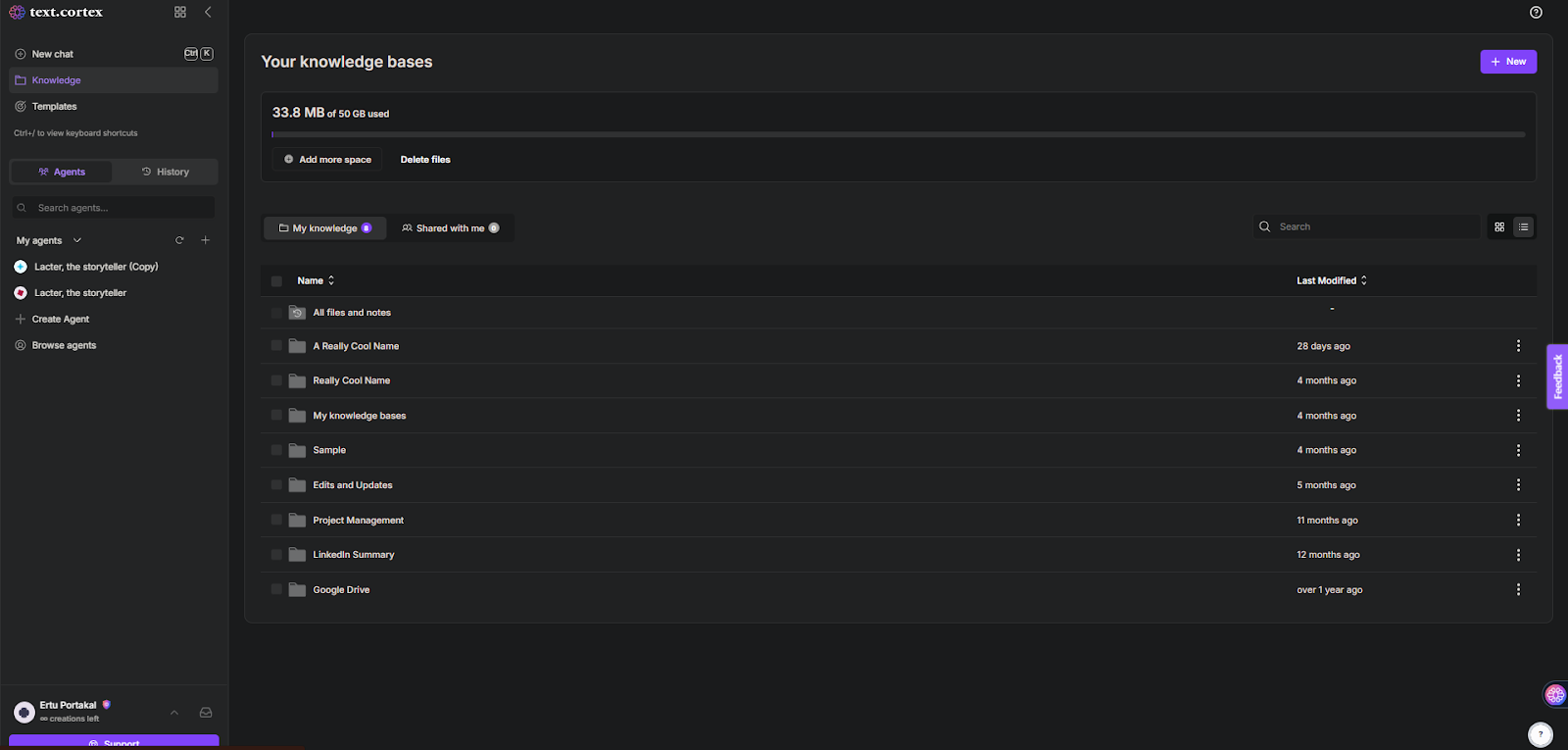
1.TextCortex ウェブアプリケーションに移動する。Knowledge "タブをクリックし、"+New "ボタンを押す。
また、まだナレッジベースに追加していないアップロードファイルがある場合は、「アップロード履歴」タブで見つけることができます。
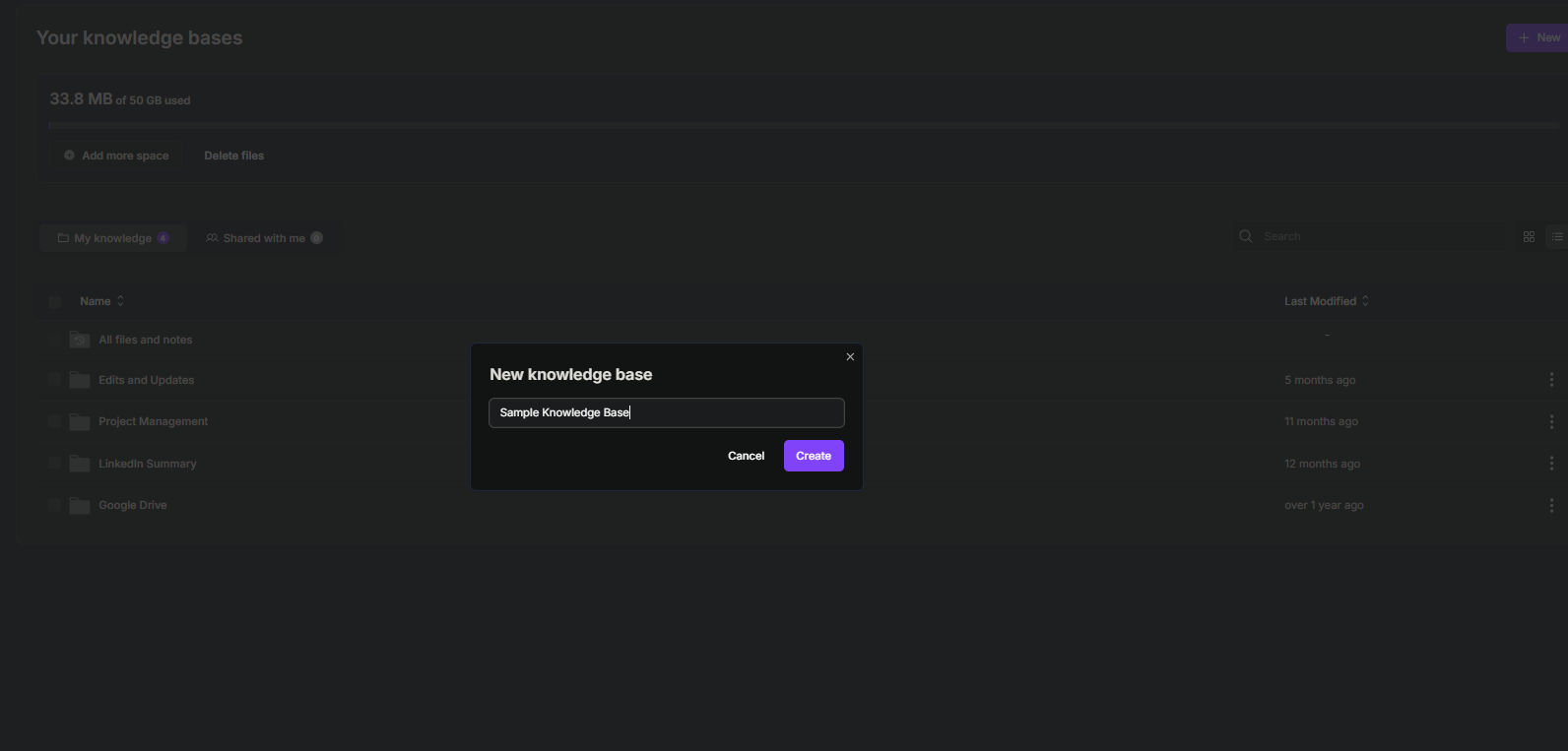
2.ナレッジベースにクールな名前を付け、「作成」ボタンをクリックします。
3.ナレッジベースを作成すると、コネクタ(ドキュメント、カスタムURLなど)をアップロードできるドライブのようなビューが表示されます。
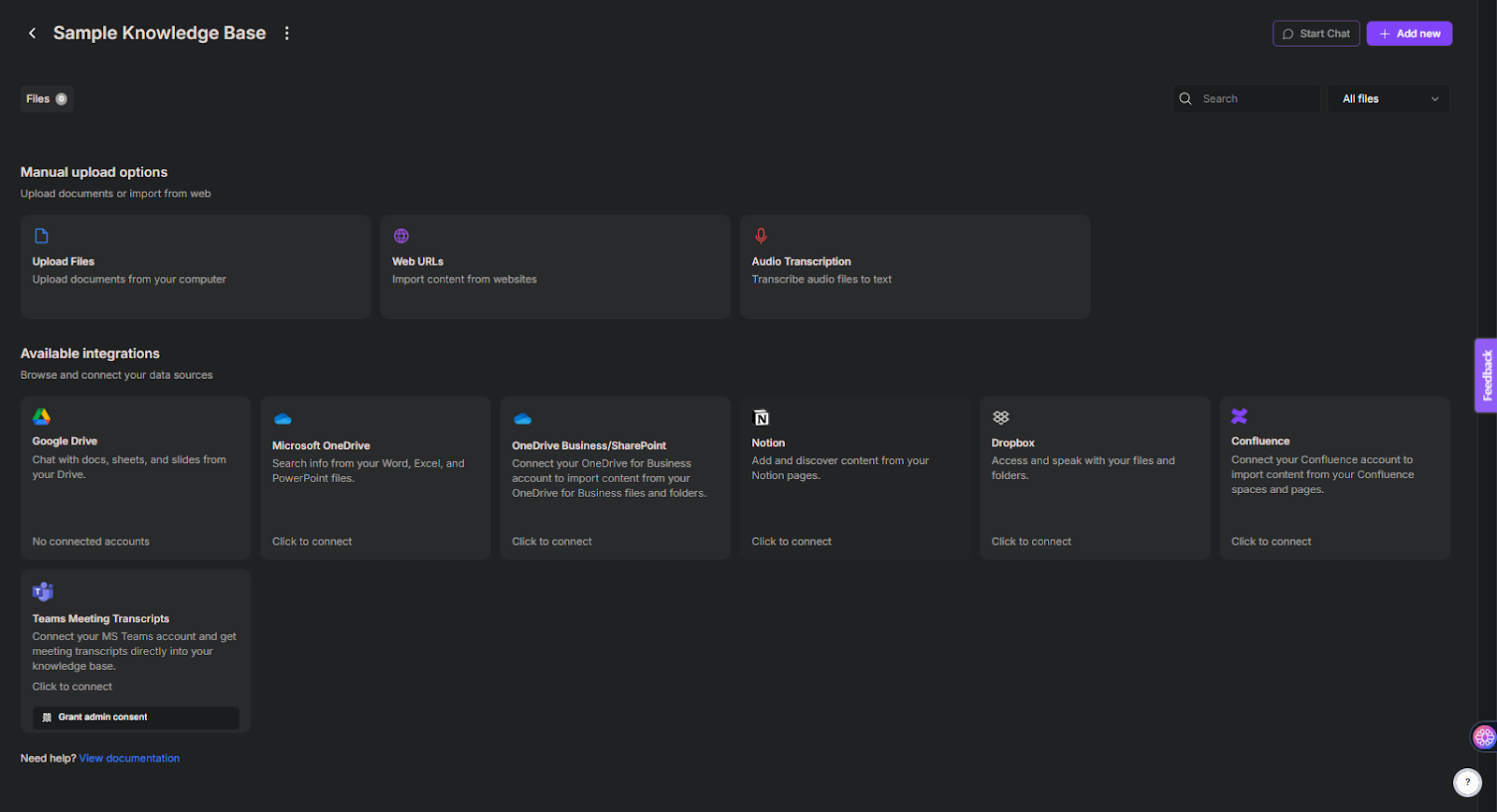
4.ナレッジベースにドキュメントをアップロードするか、カスタムURLを追加するかを選択できます。現在、PDF、CSV、PPTX、DOCXファイル形式をサポートしています。すべてのファイルはサードパーティを介さずにTextCortex 処理されます。
詳しくは「TextCortex におけるデータの取り扱いについて」をご参照ください。
プロからのアドバイス: 複数のファイルを挿入して、大量アップロードを可能にすることもできます。
5.ファイルのアップロードが完了したら、ZenoChatに向かい、"@コンテキストを追加 " ボタンを探してください。すると、AIが回答するベース情報として、複数のナレッジベースから選択できるようになります。

以上です!これで、新しいナレッジベース機能をフルに活用する準備が整いました。様々な目的のために複数のナレッジベースを作成してください。
ここでは、それを使ってできることの小さな例を紹介します!⬇️

プロからのアドバイス
あなたのAI に質問するときは、必ず具体的にしてください。あなたのAI は、あなたの指導と同じくらい有能であることを忘れないでください。あなたがより具体的な指示を出せば出すほど、あなたはより良い結果を 得ることができます。
よくある質問
自分のデータでChatGPTをトレーニングできますか?
はい、ChatGPTのAPI カスタムGPT機能を使用することで、独自のデータを使用してChatGPTを訓練することができます。しかし、TextCortexナレッジベースを活用することで、会話AIアシスタントZenoChatをアップロードしてトレーニングすることができます。ZenoChatを通じて、カスタムデータをアップロードし、Google Drive、Notion、Microsoft OneDriveなどのデータソースを接続することができます。
ファイルを使ってChatGPTをトレーニングするには?
カスタムデータでChatGPTをトレーニングするには、次の手順に従ってください:
- ステップ1:Pythonのインストールとアップグレード
- ステップ2:コードエディター(VS Codeなど)をインストールする。
- ステップ 3:API キーとシークレットキーの生成
- ステップ4:モデルの選択とナレッジベースの作成
- ステップ5:スクリプトの作成
自社のデータでチャットボットを訓練できますか?
あなたのデータで訓練されたチャットボットは、日常業務や専門的なタスクを支援することができます。例えば、ZenoChat byTextCortex AIチャットボットを自分のデータで訓練し、反復タスクを迅速かつ簡単に完了するために活用することができます。さらに、自分の声のトーンでZenoChatを構築し、電子メールへの返信や記事の執筆などのタスクに使用することもできます。
.png)
.png)
.png)