.png)
La technologie de l'intelligence artificielle a évolué, passant des chatbots à l'utilisation d'agents IA et à l'automatisation. Auparavant utilisée uniquement sous forme de chatbots dotés de fonctions telles que la recherche basée sur la base de connaissances, la technologie IA est désormais employée avec divers outils d'automatisation, pour automatiser entièrement les tâches répétitives, et surtout par les entreprises pour gagner du temps et réduire la charge de travail. Cette évolution oblige les agents IA à prendre des précautions contre un nouveau type d'attaque : les attaques par injection de prompt, qui occupent la première place du classement OWASP Top 10 des vulnérabilités des applications LLM depuis la première publication de la liste et restent en tête de l'édition 2025. Découvrons ensemble comment prévenir les attaques par injection de prompt.
TL ; DR
À mesure que les agents IA évoluent, passant du statut de chatbots à celui de systèmes autonomes capables de gérer des outils et des flux de travail réels, ils deviennent des cibles de choix pour les attaques par injection de prompts, ces astuces textuelles qui manipulent les modèles pour les pousser à divulguer des données ou à prendre des décisions préjudiciables. Pour s’en défendre, il faut mettre en place des contrôles à plusieurs niveaux : nettoyer les entrées, restreindre les privilèges, impliquer les humains dans les actions critiques, filtrer les sorties et surveiller les anomalies en temps réel. Combine ça avec une autorisation stricte des outils, la conformité réglementaire et des journaux d’audit détaillés. Si tu as besoin d’une plateforme prête pour l’entreprise qui combine l’automatisation IA avec les garanties SOC 2, ISO 27001 et RGPD, TextCortex une infrastructure sécurisée conçue exactement pour ça.
Qu'est-ce que l'injection rapide ?
L'injection de prompt est une méthode d'attaque textuelle utilisée par les pirates pour manipuler le comportement et les résultats d'un grand modèle linguistique. Les attaques par injection de prompt comportent des risques tels que le vol de données, l'accès non autorisé, la génération de contenus préjudiciables, le non-respect des directives et la prise de mauvaises décisions. Cette technique consiste à introduire des entrées spécifiques et à modifier les résultats du modèle afin de le manipuler. Il existe deux types d'injection de prompt : directe et indirecte.
Injection directe
L'injection directe de prompt se produit sur les plateformes où l'attaquant interagit directement avec le grand modèle linguistique. Par exemple, les fenêtres de discussion qui permettent d'interagir avec ce modèle constituent un terrain propice à l'injection directe de prompt. Comme cette méthode d'attaque est directe, elle est relativement facile à bloquer et à contrer.
Injection indirecte de la ligne de commande
L'injection indirecte de prompt se produit dans des situations où les grands modèles linguistiques (LLM) peuvent interagir avec des ressources externes. Par exemple, lorsque les LLM interagissent avec des sites web ou des bases de données, ou accordent des autorisations de téléchargement de fichiers, il y a un risque d'injection indirecte de prompt. Cette menace prend rapidement de l'ampleur : selon une analyse de Palo Alto Networks, les analyses de contenu web effectuées par Google ont révélé une augmentation de 32 % du contenu malveillant conçu pour l'injection indirecte de prompt entre novembre 2025 et février 2026.
Comment éviter une injection précoce ?
Il existe plusieurs mesures que tu peux prendre pour éviter une injection prématurée. Découvrons-les étape par étape.
1. Nettoyage des données d'entrée
La première méthode pour prévenir l'injection de prompts consiste à définir quelles entrées ton modèle linguistique de grande envergure acceptera et lesquelles seront signalées comme malveillantes et ne seront pas traitées. Par exemple, tu devrais apprendre à ton modèle à ne pas traiter les entrées qui l'obligent à ignorer les commandes et les précautions précédentes lors d'un jeu de rôle. Les entrées qui utilisent trop de ponctuation risquent également de perturber le comportement du modèle. La première mesure et le premier rempart que tu mettras en place consistent à limiter l'impact que les entrées brutes auront sur ton modèle.
2. Réduction des privilèges
Un agent IA ne devrait avoir accès qu'aux informations dont il a besoin et qu'il va utiliser. Ainsi, en cas d'injection de commande, l'agent IA peut éviter de causer des dommages graves. Le rapport « 2025 Cost of a Data Breach » d’IBM a révélé que 97 % des organisations ayant subi des violations liées à l’IA ne disposaient pas de contrôles d’accès adéquats à l’IA, ce qui confirme qu’un agent IA que tu utilises uniquement pour lire tes e-mails ne devrait pas avoir besoin d’accéder à la rédaction et à l’envoi d’e-mails, ni de transférer tes e-mails vers un autre document pour les envoyer sur un autre support.
3. Intervention humaine
Même si les agents IA peuvent automatiser la plupart des tâches, il est risqué de les utiliser pour une automatisation complète, surtout pour les tâches critiques. C'est pourquoi, dans des domaines critiques comme les virements bancaires, l'émission de factures, l'envoi d'e-mails et les processus de paiement, tu dois empêcher l'agent IA de prendre la décision finale et t'assurer qu'un humain s'en charge. Ainsi, en cas d'attaque par injection de commande, l'agent IA pourrait soumettre les processus critiques au contrôle humain avant leur achèvement.
4. Filtrage de la sortie
L'injection de prompt consiste à manipuler la sortie d'agents IA ou de grands modèles linguistiques par le biais de l'entrée. Tu peux donc contourner la plupart des attaques par injection de prompt sans subir de dommages en filtrant la sortie de l'agent IA ou du grand modèle linguistique.
5. Détection en temps réel des injections de prompts
Des classificateurs spécialisés et des moteurs de reconnaissance de formes analysent en permanence les données entrantes et sortantes, identifiant les instructions à risque, les attaques potentielles et les structures malveillantes. Dès qu’une attaque par injection de prompt est détectée, la génération de sortie est bloquée. Les autorisations et les actions de l'agent IA sont restreintes, ce qui empêche toute attaque potentielle par injection de prompt. Ce niveau de défense est crucial : des études en sécurité montrent que 73 % des systèmes d'IA évalués lors d'audits de sécurité sont exposés à des vulnérabilités d'injection de prompt, mais les méthodes de détection actuelles ne repèrent que 23 % des attaques sophistiquées sans analyse en temps réel dédiée.
6. Surveillance comportementale et détection des anomalies
Les systèmes de surveillance comportementale et de détection des anomalies interrogent des sources de données inhabituelles ; ils détectent toute requête anormale et la signalent à l'utilisateur. Cela te permet de surveiller simultanément ton agent IA ou ton modèle linguistique de grande envergure et de détecter directement les attaques potentielles par injection de requêtes, comme par exemple lorsque des agents IA tentent soudainement d'effectuer 500 API .
7. Autorisation d'utilisation des outils
Les agents IA ont chaque jour accès à un nombre croissant d'applications et d'outils tiers. Cela fait de l'utilisation non autorisée de ces outils une cible idéale pour les attaques par injection de ligne de commande. En définissant quels outils peuvent être utilisés par qui et dans quelles conditions, tu peux protéger ton agent IA contre ces attaques et éviter qu'il ne devienne un bot à l'origine de fuites de données. Si ta plateforme d'agents IA te permet d'autoriser des membres et de gérer leurs autorisations, tu as déjà une longueur d'avance.
8. Harmonisation réglementaire
Les réglementations internationales garantissent que les agents IA sont protégés contre bien plus que la simple génération de contenu malveillant, et les attaques par injection de prompt sur les agents IA en font partie. Il convient notamment de noter que le cadre de sécurité des agents IA du NIST impose une vérification par un intervenant humain pour les opérations impliquant des données à caractère personnel, les transactions dépassant des seuils définis, les actions irréversibles telles que la suppression de données, ainsi que tout accès à de nouveaux systèmes externes. Tu dois t'assurer que l'agent IA ou la plateforme d'agents IA que tu utilises est conforme aux réglementations mondiales et certifié. Cela garantit que ton agent IA fonctionne de manière plus sécurisée et résiste mieux aux attaques par injection de prompt.

9. Audit et journalisation
Veille à contrôler et à consigner chaque action et décision de l'agent IA. Cela te permettra de repérer tout comportement anormal ou d'identifier les erreurs commises par l'agent IA. Après toute attaque par injection de commande, l'analyse et l'examen des journaux te permettront de prendre des mesures préventives contre des attaques similaires.
TextCortex: une infrastructure d'agents IA sûre et sécurisée
Si tu souhaites que tes agents IA et les modèles d'IA que tu intègres dans ton entreprise soient à la fois efficaces et fiables, TextCortex la solution qu'il te faut. TextCortex ses utilisateurs une expérience IA sécurisée et sûre, ainsi qu'un accès aux dernières fonctionnalités d'automatisation et d'IA. Les fonctionnalités principales proposées par TextCortex :
- Agents IA pour l'automatisation
- Bases de connaissances
- Compétences
- Navigateur Extension
- Connecteurs
- Sans couture Integrations
- Créateur d'agent IA
- Plusieurs bibliothèques de modèles de langage (LLM), notamment Claude Opus 4.7 et GPT-5.5
- Générateurs d'images multiples
- Accès au Web
De plus, TextCortex toutes ces fonctionnalités avec une sécurité de pointe.
TextCortex : sécurité et sûreté grâce à TextCortex
TextCortex diverses mesures de sécurité pour protéger les données sensibles de ses utilisateurs. Tu peux accéder à l'ensemble des programmes et informations de sécurité TextCortex via ce lien. Les premières offres TextCortex en matière de sécurité de l'IA pour les entreprises concernent la conformité et les certifications. Outre la conformité aux dispositions de la loi européenne sur l'IA et au RGPD, TextCortex les certifications SOC 2 Type I, SOC 2 Type II et ISO 27001.
Politiques
TextCortex des politiques dans quatre domaines différents afin d'offrir aux utilisateurs une expérience d'IA sûre et sécurisée :
- Sécurité des applications
- Sécurité des données et confidentialité
- Sécurité des infrastructures
- Opérations de sécurité

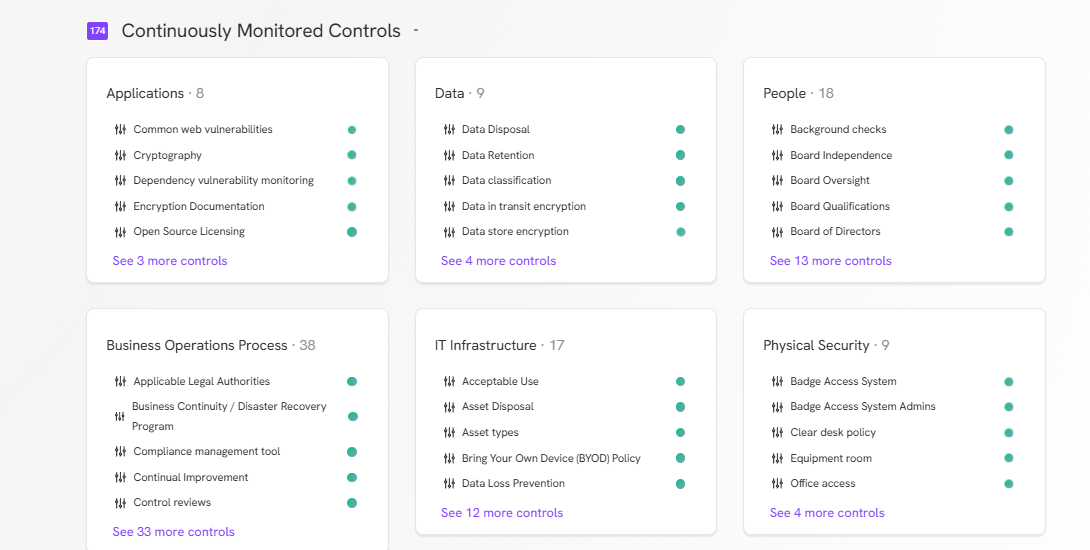
Commandes surveillées en continu
Avant d'intégrer TextCortex ton entreprise, sache qu'il te permet de surveiller en continu un large éventail de contrôles. Avec TextCortex, tu peux surveiller les contrôles relevant des catégories suivantes :
- Applications
- Données
- Les gens
- Processus opérationnel
- Infrastructure informatique
- Sécurité physique
- Infrastructure cloud
- Identité et contrôle d'accès
- Vie privée
- Les clients
- Suivi
- Processus de livraison des produits
- Fournisseurs

Questions fréquemment posées
C'est quoi exactement l'injection rapide, et pourquoi est-ce que ça devrait intéresser mon entreprise ?
L'injection de prompt, c'est quand un pirate insère du texte malveillant dans le flux d'entrée d'un agent IA pour le piéger et l'amener à ignorer ses instructions, à divulguer des données ou à effectuer des actions non autorisées. Ce n'est pas un risque théorique : Snyk a découvert que 36 % des compétences ClawHub contiennent des injections de prompt détectables, et les entreprises sont déjà confrontées à de véritables vulnérabilités (CVE) liées à l'IA agentique.
Quelle est la différence entre l'injection directe et l'injection indirecte ?
L'injection directe de ligne de commande se produit lorsqu'un pirate saisit une commande malveillante directement dans une interface de chat, en essayant de prendre le contrôle de la ligne de commande du système sur-le-champ. L'injection indirecte de ligne de commande est plus insidieuse : le pirate dissimule des instructions malveillantes dans une ressource externe à laquelle l'agent a accès, comme un site web, un fichier PDF ou une entrée de base de données.
Est-ce que la validation des entrées suffit à elle seule à empêcher l'injection dans la ligne de commande ?
La validation des entrées est ton premier bouclier, mais elle ne constitue pas à elle seule une forteresse. Elle fonctionne en signalant et en bloquant des schémas tels que les préfixes de jeu de rôle, les expressions du type « ignorer les instructions précédentes » ou la ponctuation excessive visant à contourner les délimiteurs. Le problème, c'est que les attaquants trouvent sans cesse de nouvelles façons de dissimuler leurs entrées. La validation te fait gagner du temps et détecte les tentatives évidentes, mais elle doit être associée à des restrictions de privilèges, au filtrage des sorties et à la surveillance pour être vraiment efficace.
Y a-t-il un moyen de détecter l'injection de ligne de commande en temps réel ?
Oui. Des classificateurs spécialisés et des moteurs de reconnaissance de formes peuvent analyser en continu aussi bien les invites entrantes que les réponses sortantes, à la recherche de structures malveillantes telles que des modifications d'instructions ou des violations de délimiteurs. Lorsqu'une signature de menace est détectée, le système peut bloquer la requête, restreindre les autorisations de l'agent ou rediriger le trafic vers une solution de secours plus sûre. Microsoft et d'autres plateformes proposent des protections d'invite et des passerelles IA qui font office de couche de contrôle en temps réel.
Les réglementations internationales exigent-elles vraiment des mesures de protection contre les injections malveillantes ?
Des réglementations telles que la loi européenne sur l'IA, le cadre de gestion des risques liés à l'IA du NIST et la norme ISO/IEC 42001 exigent de plus en plus de transparence, de contrôle humain et de gestion des risques pour les systèmes d'IA. Bien qu'aucune d'entre elles n'utilise littéralement l'expression « injection de prompt », l'obligation d'empêcher toute manipulation non autorisée, toute fuite de données et toute production de résultats préjudiciables correspond directement à la lutte contre l'injection de prompt.
.png)
.png)
.png)