.png)
Kunstmatige intelligentie heeft zich ontwikkeld van chatbots naar het gebruik van AI-agenten en automatisering. Waar AI-technologie vroeger alleen werd gebruikt in chatbots met functies als kennisgebaseerd zoeken, wordt het nu ingezet in allerlei tools voor automatisering, de volledige automatisering van repetitieve taken, en vooral door bedrijven om tijd en werk te besparen. Door deze verschuiving moeten AI-agenten voorzorgsmaatregelen nemen tegen een nieuw soort aanval: prompt-injectieaanvallen. Deze staan al sinds de eerste publicatie van de OWASP Top 10 voor LLM-toepassingen op nummer 1 en blijven ook in de editie van 2025 bovenaan staan. Laten we eens kijken hoe je prompt-injectieaanvallen kunt voorkomen.
TL; DR
Naarmate AI-agenten zich ontwikkelen van chatbots tot autonome systemen die met echte tools en workflows werken, worden ze een belangrijk doelwit voor prompt-injectieaanvallen: tekstuele trucs die modellen manipuleren om gegevens te lekken of schadelijke beslissingen te nemen. Om je hiertegen te verdedigen, moet je meerdere beveiligingslagen aanbrengen: zuiver invoer, beperk rechten, betrek mensen bij kritieke acties, filter uitvoer en controleer in realtime op afwijkingen. Combineer dat met strikte toolautorisatie, naleving van regelgeving en gedetailleerde auditlogs. Als je een platform nodig hebt dat geschikt is voor grote bedrijven en dat AI-automatisering combineert met SOC 2-, ISO 27001- en GDPR-waarborgen, TextCortex een veilige infrastructuur die precies daarvoor is gebouwd.
Wat is Prompt Injection?
Prompt-injectie is een tekstuele aanvalsmethode die aanvallers gebruiken om het gedrag en de output van een groot taalmodel te manipuleren. Aanvallen via prompt-injectie brengen risico’s met zich mee, zoals gegevensdiefstal, ongeoorloofde toegang, het genereren van schadelijke inhoud, het overtreden van richtlijnen en verkeerde besluitvorming. Het gaat erom dat je specifieke invoer invoert en de output van het model verandert om het model te manipuleren. Prompt-injectie kent twee vormen: direct en indirect.
Directe injectie
Directe prompt-injectie komt voor op platforms waar de aanvaller rechtstreeks met het grote taalmodel communiceert. Zo zijn bijvoorbeeld chatvensters waarmee je met het grote taalmodel kunt communiceren een ideaal doelwit voor directe prompt-injectie. Omdat deze aanvalsmethode rechtstreeks is, is ze relatief eenvoudig te blokkeren en te bestrijden.
Indirecte promptinjectie
Indirecte prompt-injectie komt voor in situaties waarin grote taalmodellen (LLM’s) kunnen communiceren met externe bronnen. Als LLM’s bijvoorbeeld communiceren met websites of databases, of toestemming geven om bestanden te uploaden, bestaat er een risico op indirecte prompt-injectie. Deze dreiging neemt snel toe: uit scans van webcontent door Google bleek tussen november 2025 en februari 2026 een toename van 32% in kwaadaardige content die is ontworpen voor indirecte prompt-injectie, volgens een analyse van Palo Alto Networks.
Hoe voorkom je dat er meteen een injectie wordt toegediend?
Er zijn verschillende maatregelen die je kunt nemen om een te snelle injectie te voorkomen. Laten we deze maatregelen stap voor stap bekijken.
1. Invoeropschoning
De eerste manier om prompt-injectie te voorkomen, is door in te stellen welke invoer je grote taalmodel accepteert en welke als schadelijk wordt gemarkeerd en niet wordt verwerkt. Je moet je model bijvoorbeeld leren om geen invoer te verwerken waarbij het eerdere opdrachten en voorzorgsmaatregelen tijdens rollenspellen moet negeren. Ook invoer met te veel leestekens vormt een risico omdat het het gedrag van het model kan verstoren. De eerste maatregel en het eerste beschermingsmechanisme dat je neemt, is het beperken van de invloed die pure invoer op je model heeft.
2. Beperking van rechten
Een AI-agent zou alleen toegang moeten hebben tot de informatie die hij nodig heeft en ook daadwerkelijk gaat gebruiken. Zo kan de AI-agent in het geval van prompt-injectie voorkomen dat er ernstige schade ontstaat. Uit het rapport 'Cost of a Data Breach 2025' van IBM bleek dat 97% van de organisaties die te maken hadden met AI-gerelateerde inbreuken, geen goede toegangscontroles voor AI had. Dit onderstreept dat een AI-agent die je alleen gebruikt om je e-mails te lezen, geen toegang nodig heeft om e-mails te schrijven en te versturen, of om je e-mails over te zetten naar een ander document en ze naar een ander medium te sturen.
3. Menselijke tussenkomst
Hoewel AI-agenten de meeste taken kunnen automatiseren, is het gevaarlijk om ze in te zetten voor volledige automatisering, vooral bij kritieke taken. Daarom moet je er op kritieke gebieden zoals geld overmaken, facturen versturen, e-mails versturen en betalingsprocessen voor zorgen dat de AI-agent niet de uiteindelijke beslissing neemt, maar dat een mens dat doet. Op die manier kan de AI-agent bij een prompt-injectieaanval kritieke processen nog vóór voltooiing aan menselijke controle onderwerpen.
4. Uitvoerfiltering
Bij prompt-injectie wordt de uitvoer van AI-agenten of grote taalmodellen gemanipuleerd via de invoer. Daarom kun je de meeste prompt-injectieaanvallen zonder schade afweren door de uitvoer van de AI-agent of het grote taalmodel te filteren.
5. Detectie van realtime prompt-injectie
Gespecialiseerde classifiers en patroonherkenningsengines scannen continu inkomende en uitgaande gegevens, waarbij ze risicovolle instructies, mogelijke aanvallen en schadelijke structuren opsporen. Zodra er een prompt-injectieaanval wordt gedetecteerd, wordt het genereren van uitvoer geblokkeerd. De rechten en acties van de AI-agent worden beperkt, waardoor de potentiële prompt-injectieaanval wordt voorkomen. Deze verdedigingslaag is cruciaal: uit beveiligingsonderzoek blijkt dat 73% van de AI-systemen die bij beveiligingsaudits zijn beoordeeld, kwetsbaar is voor prompt-injectie, maar dat de huidige detectiemethoden slechts 23% van de geavanceerde aanvallen opsporen zonder dat er speciale realtime scans worden uitgevoerd.
6. Gedragscontrole en detectie van afwijkingen
Systemen voor gedragsmonitoring en het opsporen van afwijkingen doorzoeken ongebruikelijke gegevensbronnen; ze detecteren afwijkende prompts en sturen deze door naar de gebruiker. Zo kun je je AI-agent of groot taalmodel continu in de gaten houden en direct mogelijke prompt-injectieaanvallen opsporen, zoals wanneer AI-agenten plotseling 500 API proberen te doen.
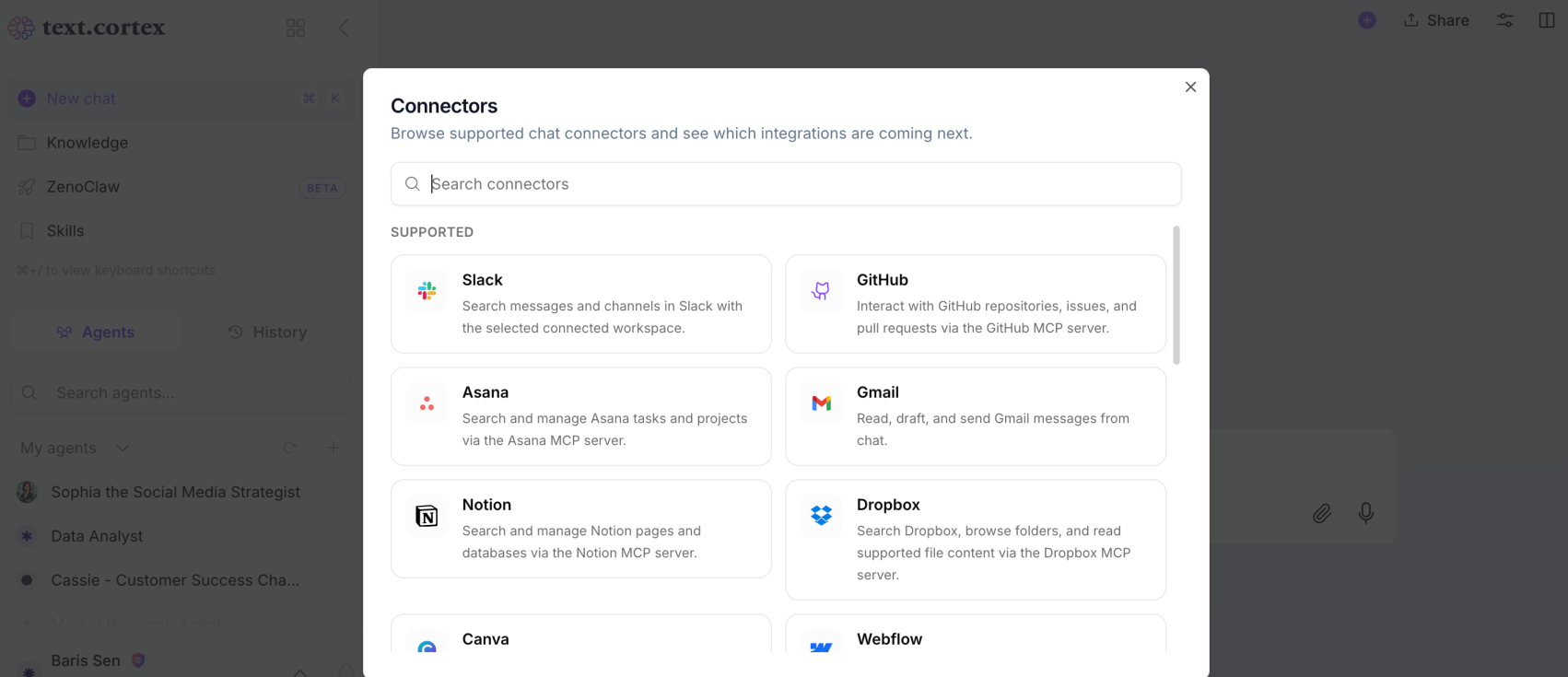
7. Toestemming voor het gebruik van de tool
AI-agenten krijgen elke dag toegang tot steeds meer applicaties en tools van derden. Hierdoor vormt onjuist geautoriseerd gebruik van tools een perfect doelwit voor prompt-injectieaanvallen. Door te bepalen welke tools door wie en onder welke voorwaarden mogen worden gebruikt, kun je je AI-agent beschermen tegen prompt-injectieaanvallen en voorkomen dat hij verandert in een bot die gegevens lekt. Als je AI-agentplatform je de mogelijkheid biedt om leden te autoriseren en hun rechten te beheren, heb je al een voorsprong.
8. Harmonisatie van regelgeving
Wereldwijde regelgeving zorgt ervoor dat AI-agenten niet alleen worden beschermd tegen het genereren van schadelijke inhoud, maar ook tegen aanvallen waarbij prompts in AI-agenten worden geïnjecteerd. Het NIST-beveiligingskader voor AI-agenten schrijft met name voor dat er een menselijke controle moet plaatsvinden bij bewerkingen waarbij persoonsgegevens betrokken zijn, bij transacties die bepaalde drempels overschrijden, bij onomkeerbare acties zoals het verwijderen van gegevens, en bij elke toegang tot nieuwe externe systemen. Je moet ervoor zorgen dat de AI-agent of het AI-agentplatform dat je gebruikt voldoet aan wereldwijde regelgeving en gecertificeerd is. Dit zorgt ervoor dat je AI-agent veiliger werkt en beter bestand is tegen prompt injection-aanvallen.

9. Controle en logboekregistratie
Zorg ervoor dat je elke handeling en beslissing van de AI-agent controleert en vastlegt. Zo kun je afwijkend gedrag opmerken of vaststellen waar de AI-agent een fout heeft gemaakt. Na een aanval met prompt-injectie helpen het controleren en doornemen van de logbestanden je om voorzorgsmaatregelen te nemen tegen soortgelijke aanvallen.
TextCortex: Veilige en betrouwbare infrastructuur voor AI-agenten
Als je wilt dat je AI-agenten en de AI-modellen die je in je bedrijf integreert zowel effectief als betrouwbaar zijn, TextCortex de oplossing voor jou. TextCortex zijn gebruikers zowel een veilige AI-ervaring als toegang tot de nieuwste automatiserings- en AI-functies. TextCortex de belangrijkste functies van TextCortex :
- AI-agenten voor automatisering
- Kennisbanken
- Vaardigheden
- Browser Extension
- Aansluitingen
- Naadloos Integrations
- AI-agentbouwer
- Meerdere LLM-bibliotheken, waaronder Claude Opus 4.7 en GPT-5.5
- Meerdere afbeeldingsgeneratoren
- Webtoegang
Bovendien TextCortex al deze functies met de allernieuwste beveiliging.
TextCortex : beveiliging en veiligheid
TextCortex verschillende beveiligingsmaatregelen om de gevoelige gegevens van zijn gebruikers te beschermen. Via deze link kun je alle beveiligingsprogramma’s en informatie TextCortex bekijken. De eerste AI-beveiligingsoplossingen voor bedrijven TextCortex zijn de nalevingsverklaringen en certificeringen. Naast naleving van de EU-AI-wet en de AVG TextCortex SOC 2 Type I-, SOC 2 Type II- en ISO 27001-certificeringen.
Beleid
TextCortex beleid op vier verschillende gebieden om gebruikers een veilige AI-ervaring te bieden:
- Applicatiebeveiliging
- Gegevensbeveiliging en privacy
- Beveiliging van de infrastructuur
- Beveiligingsactiviteiten

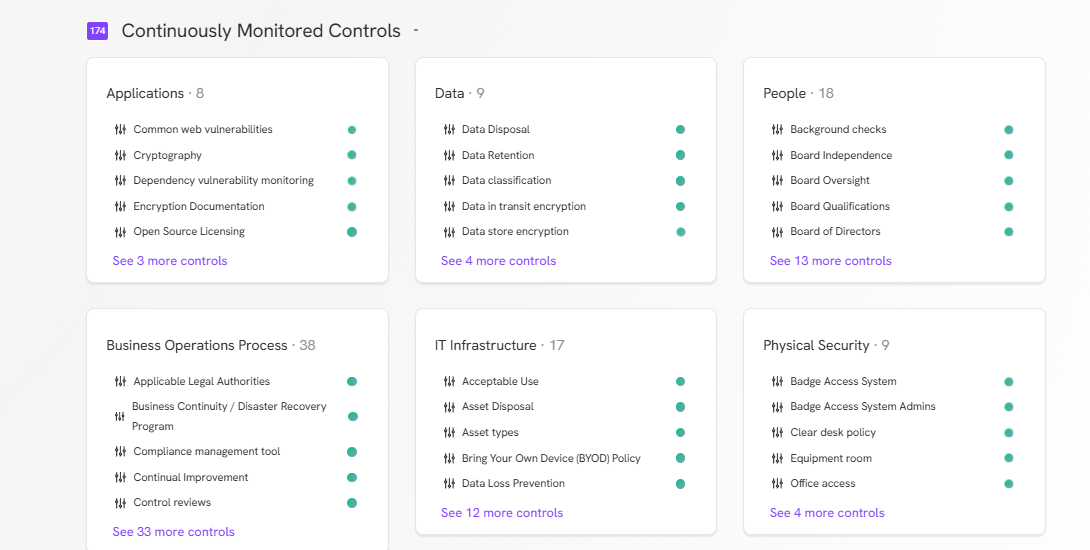
Continu bewaakte bedieningselementen
Voordat je TextCortex je bedrijf implementeert, is het goed om te weten dat je hiermee continu een breed scala aan controles kunt monitoren. Met TextCortex kun je controles monitoren onder de volgende rubrieken:
- Toepassingen
- Gegevens
- Mensen
- Bedrijfsproces
- IT-infrastructuur
- Fysieke beveiliging
- Cloudinfrastructuur
- Identiteits- en toegangsbeheer
- Privacy
- Klanten
- Monitoring
- Het leveringsproces
- Leveranciers

Veelgestelde vragen
Wat is prompt injection precies, en waarom zou mijn bedrijf hier aandacht aan moeten besteden?
Bij prompt-injectie sluipt een aanvaller kwaadaardige tekst in de invoerstroom van een AI-agent om het model te misleiden, zodat het zijn instructies negeert, gegevens lekt of ongeoorloofde acties onderneemt. Dit is geen theoretisch risico: Snyk ontdekte dat 36% van de ClawHub-skills detecteerbare prompt-injectie bevat, en bedrijven zien nu al echte CVE’s die verband houden met agentische AI.
Wat is het verschil tussen directe en indirecte snelle injectie?
Directe prompt-injectie vindt plaats wanneer een aanvaller een kwaadaardige opdracht rechtstreeks in een chatinterface intypt, in een poging om de systeemprompt ter plekke te overschrijven. Indirecte prompt-injectie is slimmer: de aanvaller verbergt kwaadaardige instructies in een externe bron die de agent gebruikt, zoals een website, een pdf of een database-item.
Kan het opschonen van invoer alleen prompt-injectie voorkomen?
Het opschonen van invoer is je eerste verdedigingslinie, maar het is op zichzelf geen onneembare vesting. Het werkt door patronen te herkennen en te blokkeren, zoals rollenspel-voorvoegsels, "negeer eerdere instructies" of overmatig gebruik van leestekens waarmee de grenzen van scheidingstekens worden overschreden. Het probleem is dat aanvallers voortdurend nieuwe manieren vinden om hun invoer te verbergen. Sanitization geeft je wat tijd en vangt de voor de hand liggende pogingen op, maar het moet worden gecombineerd met beperkingen op rechten, outputfiltering en monitoring om echt effectief te zijn.
Is er een manier om prompt-injectie in realtime te detecteren?
Ja. Gespecialiseerde classifiers en pattern-matching-engines kunnen zowel inkomende prompts als uitgaande reacties continu scannen, op zoek naar kwaadaardige patronen zoals het overschrijven van instructies of het doorbreken van scheidingstekens. Als er een overeenkomst met een bedreigingssignatuur wordt gevonden, kan het systeem het verzoek blokkeren, de rechten van de agent beperken of het verkeer omleiden naar een veiliger alternatief. Microsoft en andere platforms bieden prompt shields en AI-gateways aan die als deze realtime controlaar fungeren.
Vereisen internationale regelgevingen eigenlijk wel maatregelen tegen snelle injecties?
Regelgeving zoals de EU-AI-wet, het NIST-kader voor AI-risicobeheer en ISO/IEC 42001 stelt steeds hogere eisen aan transparantie, menselijk toezicht en risicobeheer voor AI-systemen. Hoewel in geen van deze documenten de term "prompt injection" letterlijk wordt genoemd, sluit de eis om ongeoorloofde manipulatie, datalekken en schadelijke output te voorkomen naadloos aan bij maatregelen tegen prompt injection.
.png)
.png)
.png)