.png)
Die Technologie der künstlichen Intelligenz hat sich von Chatbots hin zum Einsatz von KI-Agenten und Automatisierung weiterentwickelt. Früher nur als Chatbots mit Funktionen wie der wissensbasierten Suche genutzt, wird KI-Technologie heute in verschiedenen Tools zur Automatisierung, zur vollständigen Automatisierung sich wiederholender Aufgaben und insbesondere von Unternehmen eingesetzt, um Zeit und Arbeitsaufwand zu sparen. Dieser Wandel erfordert, dass KI-Agenten Vorkehrungen gegen eine neue Art von Angriff treffen: Prompt-Injection-Angriffe, die seit der ersten Veröffentlichung der OWASP Top 10 für LLM-Anwendungen auf Platz 1 der Schwachstellen stehen und auch in der Ausgabe 2025 an der Spitze bleiben. Lass uns gemeinsam Wege finden, um Prompt-Injection-Angriffe zu verhindern.
TL; DR
Da sich KI-Agenten von Chatbots zu autonomen Systemen entwickeln, die mit echten Tools und Arbeitsabläufen umgehen, werden sie zu Hauptzielen für Prompt-Injection-Angriffe – textbasierte Tricks, die Modelle dazu manipulieren, Daten preiszugeben oder schädliche Entscheidungen zu treffen. Sich dagegen zu schützen bedeutet, mehrschichtige Kontrollen einzurichten: Eingaben bereinigen, Berechtigungen einschränken, Menschen bei kritischen Aktionen einbeziehen, Ausgaben filtern und in Echtzeit auf Anomalien überwachen. Kombiniere das mit strenger Tool-Autorisierung, Einhaltung gesetzlicher Vorschriften und detaillierten Audit-Protokollen. Wenn du eine unternehmensgerechte Plattform brauchst, die KI-Automatisierung mit SOC 2-, ISO 27001- und DSGVO-Sicherheitsvorkehrungen verbindet, TextCortex eine sichere Infrastruktur, die genau dafür entwickelt wurde.
Was ist Prompt Injection?
Prompt-Injection ist eine textbasierte Angriffsmethode, mit der Angreifer das Verhalten und die Ausgabe eines großen Sprachmodells manipulieren. Prompt-Injection-Angriffe bergen Risiken wie Datendiebstahl, unbefugten Zugriff, die Erzeugung schädlicher Inhalte, Verstöße gegen Richtlinien und falsche Entscheidungsfindungen. Dabei werden bestimmte Eingaben eingefügt und die Ausgabe des Modells verändert, um das Modell zu manipulieren. Es gibt zwei Arten von Prompt-Injection: direkte und indirekte.
Direkte Einspeisung
Eine direkte Prompt-Injektion findet auf Plattformen statt, auf denen der Angreifer direkt mit dem großen Sprachmodell interagiert. Beispielsweise sind Chat-Fenster, die eine Interaktion mit dem großen Sprachmodell ermöglichen, ein idealer Angriffspunkt für eine direkte Prompt-Injektion. Da es sich um eine direkte Angriffsmethode handelt, lässt sie sich relativ leicht blockieren und abwehren.
Indirekte Eingabeaufforderung
Indirekte Prompt-Injektion tritt in Szenarien auf, in denen große Sprachmodelle (LLMs) mit externen Ressourcen interagieren können. Wenn LLMs beispielsweise mit Websites oder Datenbanken interagieren oder Berechtigungen zum Hochladen von Dateien erteilen, besteht das Risiko einer indirekten Prompt-Injection. Diese Bedrohung nimmt rapide zu: Laut einer Analyse von Palo Alto Networks hat Google bei der Überprüfung von Webinhalten zwischen November 2025 und Februar 2026 einen Anstieg von 32 % bei bösartigen Inhalten festgestellt, die für indirekte Prompt-Injection konzipiert sind.
Wie lässt sich eine vorzeitige Injektion verhindern?
Es gibt verschiedene Maßnahmen, die du ergreifen kannst, um eine sofortige Injektion zu verhindern. Lass uns diese Maßnahmen Schritt für Schritt durchgehen.
1. Eingabevalidierung
Die erste Methode zur Verhinderung von Prompt-Injection besteht darin, festzulegen, welche Eingaben dein großes Sprachmodell akzeptieren soll und welche als bösartig markiert und nicht verarbeitet werden. Du solltest deinem Modell beispielsweise beibringen, Eingaben nicht zu verarbeiten, die es dazu zwingen, vorherige Befehle und Vorsichtsmaßnahmen beim Rollenspiel zu ignorieren. Auch Eingaben mit übermäßigem Einsatz von Satzzeichen bergen das Risiko, das Verhalten des Modells zu stören. Die erste Maßnahme und der erste Schutzschild, den du errichten wirst, besteht darin, den Einfluss reiner Eingaben auf dein Modell einzuschränken.
2. Minimierung von Berechtigungen
Ein KI-Agent sollte nur Zugriff auf die Informationen haben, die er benötigt und auch nutzt. Auf diese Weise kann der KI-Agent in jeder Situation, in der es zu einer Prompt-Injection kommt, verhindern, dass kritischer Schaden entsteht. Der IBM-Bericht „Cost of a Data Breach 2025“ ergab, dass 97 % der Unternehmen, die KI-bezogene Sicherheitsverletzungen erlitten hatten, keine angemessenen KI-Zugriffskontrollen hatten. Dies unterstreicht, dass ein KI-Agent, den du nur zum Lesen deiner E-Mails verwendest, nicht auch Zugriff zum Verfassen und Versenden von E-Mails oder zum Übertragen deiner E-Mails in ein anderes Dokument und zum Versenden an ein anderes Medium benötigen sollte.
3. Mensch im Regelkreis
Zwar können KI-Agenten die meisten Aufgaben automatisieren, doch ist ihr Einsatz für eine vollständige Automatisierung gefährlich, insbesondere bei kritischen Aufgaben. Daher solltest du in kritischen Bereichen wie Geldüberweisungen, Rechnungsstellung, E-Mail-Versand und Zahlungsprozessen verhindern, dass der KI-Agent die endgültige Entscheidung trifft, und sicherstellen, dass ein Mensch die endgültige Entscheidung trifft. Auf diese Weise könnte der KI-Agent bei einem Prompt-Injection-Angriff kritische Prozesse vor deren Abschluss der menschlichen Kontrolle unterwerfen.
4. Ausgabefilterung
Bei der Prompt-Injection wird die Ausgabe von KI-Agenten oder großen Sprachmodellen durch die Eingabe manipuliert. Daher kannst du die meisten Prompt-Injection-Angriffe ohne Schaden abwehren, indem du die Ausgabe des KI-Agenten oder des großen Sprachmodells filterst.
5. Erkennung von Prompt-Injektionen in Echtzeit
Spezialisierte Klassifikatoren und Mustererkennungs-Engines scannen kontinuierlich eingehende Eingaben und ausgehende Ausgaben und identifizieren dabei riskante Befehle, potenzielle Angriffe und bösartige Strukturen. Sobald ein Prompt-Injection-Angriff erkannt wird, wird die Ausgabegenerierung blockiert. Die Berechtigungen und Aktionen des KI-Agenten werden eingeschränkt, wodurch der potenzielle Prompt-Injection-Angriff verhindert wird. Diese Verteidigungsebene ist entscheidend: Sicherheitsstudien zeigen, dass 73 % der in Sicherheitsaudits bewerteten KI-Systeme anfällig für Prompt-Injection-Schwachstellen sind, doch aktuelle Erkennungsmethoden fangen ohne dediziertes Echtzeit-Scanning nur 23 % der raffinierten Angriffe ab.
6. Verhaltensüberwachung und Erkennung von Anomalien
Systeme zur Verhaltensüberwachung und Anomalieerkennung greifen auf ungewöhnliche Datenquellen zu; sie erkennen alle ungewöhnlichen Eingabeaufforderungen und leiten diese an den Benutzer weiter. So kannst du deinen KI-Agenten oder dein Large-Language-Modell gleichzeitig überwachen und potenzielle Prompt-Injection-Angriffe direkt erkennen, beispielsweise wenn KI-Agenten plötzlich versuchen, 500 API zu tätigen.
7. Berechtigung zur Nutzung von Tools
KI-Agenten erhalten täglich Zugriff auf immer mehr Anwendungen und Tools von Drittanbietern. Dadurch wird die unsachgemäße Autorisierung von Tools zu einem idealen Ziel für Prompt-Injection-Angriffe. Indem du festlegst, welche Tools von wem und unter welchen Bedingungen genutzt werden dürfen, kannst du deinen KI-Agenten vor Prompt-Injection-Angriffen schützen und verhindern, dass er zu einem Bot wird, der Daten nach außen trägt. Wenn deine KI-Agenten-Plattform es dir ermöglicht, Mitglieder zu autorisieren und deren Berechtigungen zu verwalten, bist du schon einen Schritt voraus.
8. Angleichung der Rechtsvorschriften
Globale Vorschriften stellen sicher, dass KI-Agenten nicht nur vor der Erzeugung bösartiger Inhalte geschützt sind – Angriffe durch die Einfügung von Befehlen in KI-Agenten gehören ebenfalls dazu. Insbesondere schreibt das NIST-Sicherheitsrahmenwerk Bewertung KI-Agenten Bewertung vor, Bewertung Vorgänge mit personenbezogenen Daten, Transaktionen, die festgelegte Schwellenwerte überschreiten, irreversible Aktionen wie das Löschen von Daten sowie jeglichen Zugriff auf neue externe Systeme Bewertung . Du musst sicherstellen, dass der von dir verwendete KI-Agent oder die KI-Agent-Plattform den globalen Vorschriften entspricht und zertifiziert ist. Dies gewährleistet, dass dein KI-Agent sicherer arbeitet und widerstandsfähiger gegen Prompt-Injection-Angriffe ist.

9. Überwachung und Protokollierung
Stelle sicher, dass du jede Aktion und Entscheidung des KI-Agenten überprüfst und protokollierst. So kannst du ungewöhnliches Verhalten erkennen oder feststellen, wo der KI-Agent einen Fehler gemacht hat. Nach einem Prompt-Injection-Angriff helfen dir die Überprüfung und Auswertung der Protokolle dabei, Vorkehrungen gegen ähnliche Angriffe zu treffen.
TextCortex: Eine sichere Infrastruktur für KI-Agenten
Wenn du möchtest, dass deine KI-Agenten und die KI-Modelle, die du in dein Unternehmen integrierst, sowohl effektiv als auch zuverlässig sind, TextCortex die richtige Lösung für dich. TextCortex seinen Nutzern sowohl eine sichere KI-Erfahrung als auch Zugriff auf die neuesten Automatisierungs- und KI-Funktionen. TextCortex den Kernfunktionen von TextCortex :
- KI-Agenten für die Automatisierung
- Wissensdatenbanken
- Fähigkeiten
- Browser-Extension.
- Anschlüsse
- Nahtlos Integrations
- KI-Agenten-Ersteller
- Mehrere LLM-Bibliotheken, darunter Claude Opus 4.7 und GPT-5.5
- Mehrere Bildgeneratoren
- Web-Zugang
Außerdem TextCortex all diese Funktionen mit modernster Sicherheitstechnik.
TextCortex für Sicherheit und Schutz
TextCortex verschiedene Sicherheitsmaßnahmen zum Schutz der sensiblen Daten seiner Nutzer. Über diesen Link kannst du auf alle Sicherheitsprogramme und Informationen TextCortex zugreifen. Die ersten KI-Sicherheitslösungen TextCortex für Unternehmen sind die Compliance-Maßnahmen und Zertifizierungen. Neben der Einhaltung der Vorschriften des EU-KI-Gesetzes und der DSGVO TextCortex Zertifizierungen nach SOC 2 Typ I, SOC 2 Typ II und ISO 27001 TextCortex .
Richtlinien
TextCortex Richtlinien in vier verschiedenen Bereichen TextCortex , um den Nutzern eine sichere KI-Erfahrung zu bieten:
- Anwendungssicherheit
- Datensicherheit und Datenschutz
- Infrastruktursicherheit
- Sicherheitsmaßnahmen

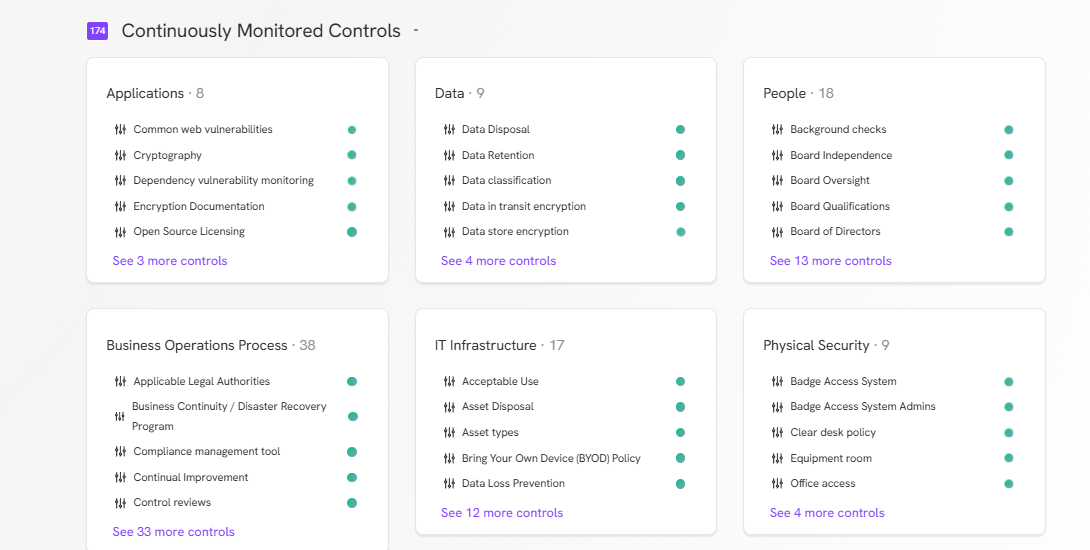
Kontinuierlich überwachte Steuerungen
Bevor du TextCortex deinem Unternehmen einsetzt, solltest du wissen, dass du damit eine Vielzahl von Kontrollpunkten kontinuierlich überwachen kannst. Mit TextCortex kannst du Kontrollpunkte unter den folgenden Rubriken überwachen:
- Anwendungen
- Daten
- Menschen
- Geschäftsablauf
- IT-Infrastruktur
- Physische Sicherheit
- Cloud-Infrastruktur
- Identitäts- und Zugriffskontrolle
- Datenschutz
- Kunden
- Überwachung
- Ablauf der Produktlieferung
- Anbieter

Häufig gestellte Fragen
Was genau ist Prompt-Injection, und warum sollte das für mein Unternehmen von Bedeutung sein?
Bei einer Prompt-Injection schleicht ein Angreifer bösartigen Text in den Eingabestrom eines KI-Agenten ein, um das Modell dazu zu bringen, seine Anweisungen zu ignorieren, Daten preiszugeben oder unbefugte Aktionen auszuführen. Das ist kein theoretisches Risiko: Snyk hat festgestellt, dass 36 % der ClawHub-Skills nachweisbare Prompt-Injections enthalten, und Unternehmen sehen bereits echte CVEs, die mit agentischer KI in Verbindung stehen.
Was ist der Unterschied zwischen direkter und indirekter Prompteinspritzung?
Eine direkte Prompt-Injektion liegt vor, wenn ein Angreifer einen bösartigen Befehl direkt in eine Chat-Oberfläche eingibt und versucht, die System-Eingabeaufforderung sofort zu überschreiben. Eine indirekte Prompt-Injektion ist heimtückischer: Der Angreifer versteckt bösartige Anweisungen in einer externen Ressource, auf die der Agent zugreift, wie beispielsweise einer Website, einer PDF-Datei oder einem Datenbankeintrag.
Kann die Eingabevalidierung allein Prompt-Injection verhindern?
Die Eingabesanierung ist dein erster Schutzschild, aber sie ist für sich allein keine Festung. Sie funktioniert, indem sie Muster wie Rollenspiel-Präfixe, „vorherige Anweisungen ignorieren“ oder übermäßige Zeichensetzung, die versucht, Begrenzungszeichen zu umgehen, markiert und blockiert. Das Problem ist, dass Angreifer ständig neue Wege finden, ihre Eingaben zu verschleiern. Die Bereinigung verschafft dir Zeit und fängt die offensichtlichen Versuche ab, muss aber mit Berechtigungsbeschränkungen, Ausgabefilterung und Überwachung kombiniert werden, um wirklich effektiv zu sein.
Gibt es eine Möglichkeit, Prompt-Injection in Echtzeit zu erkennen?
Ja. Spezielle Klassifikatoren und Mustererkennungs-Engines können sowohl eingehende Eingabeaufforderungen als auch ausgehende Antworten kontinuierlich scannen und dabei nach feindlichen Strukturen wie Anweisungsüberschreibungen oder Abgrenzungsfehlern suchen. Wenn eine Bedrohungssignatur übereinstimmt, kann das System die Anfrage blockieren, die Berechtigungen des Agenten einschränken oder den Datenverkehr an einen sichereren Fallback weiterleiten. Microsoft und andere Plattformen bieten Prompt-Shields und KI-Gateways an, die als diese Echtzeit-Kontrollschicht fungieren.
Verlangen globale Vorschriften tatsächlich Abwehrmaßnahmen gegen Injektionsangriffe?
Vorschriften wie das EU-KI-Gesetz, das NIST-Rahmenwerk für das KI-Risikomanagement und die Norm ISO/IEC 42001 verlangen zunehmend Transparenz, menschliche Aufsicht und Risikomanagement für KI-Systeme. Auch wenn in keinem dieser Dokumente der Begriff „Prompt-Injection“ wörtlich verwendet wird, lässt sich die Anforderung, unbefugte Manipulationen, Datenlecks und schädliche Ausgaben zu verhindern, direkt auf Maßnahmen zur Abwehr von Prompt-Injection zurückführen.
.png)
.png)
.png)