.png)
EU data residency refers to the physical or geographical location where an organization’s digital data is stored and processed, specifically within the borders of the European Union (EU) or the European Economic Area (EEA). EU data residency is important for enterprises and organizations in terms of regulatory compliance, data sovereignty, and user trust. If you're wondering what EU data residency means for enterprise AI stacks and want to learn about the checkboxes you need to verify before choosing an AI platform, we've got you covered!
In this article, we will explain what EU data residency is and its actual meaning for enterprise AI stacks.
TL; DR
EU data residency means storing and processing all enterprise AI data within EU or EEA borders, covering not just where the model runs but where prompts, retrieved content, context, and logs live. It differs from related concepts: residency is about location, sovereignty is about legal jurisdiction, and compliance is about meeting governance requirements. To properly evaluate an AI platform's residency claims, check four surfaces: inference (where prompts are processed and outputs generated), retrieval indexes (where company knowledge is indexed and embeddings stored), context window (how conversation history, memory, and attached files are retained and managed), and reasoning logs (operational metadata, tool traces, and observability records). A vendor claiming "hosted in Europe" without clarity on all four layers leaves compliance gaps. TextCortex addresses all four surfaces, offering 24+ EU-hosted, GDPR-compliant LLMs (including GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro, and budget alternatives like Kimi K2.6, GLM 5.2, and DeepSeek V4 Pro) via a single API, with built-in monitoring, logging, auditing, AI agents, and enterprise knowledge bases.
What EU Data Residency Means for AI
AI data residency in the EU is the fastest way for organizations and enterprises to use generative AI, AI agents, and AI models without compromising data protection. EU data residency for AI is not limited to simply storing AI model data on EU-hosted servers; it also requires that all input and output data of the model be processed within the EU or EEA borders.
Why is EU Data Residency Important?
The key to EU data residency is ensuring that data flow remains within EU borders at every step of the workflow for enterprises and organizations, preventing data leaks. EU data residency secures sensitive organizational or business information, including prompts, retrieved content, logs, outputs, and other data used or generated by AI. This allows you, as a user, to clearly track and map where your organizational data is processed, stored, and logged.
The Difference Between Data Residency, Sovereignty, and Compliance
At first glance, data residency, sovereignty, and compliance may seem to refer to the same concepts, but they are different parts of similar issues. We can briefly summarize the difference between these three concepts as follows:
- Data Residency: Where data is stored or processed.
- Data Sovereignty: Which legal jurisdiction may affect that data.
- Compliance: Whether the overall setup meets legal and governance requirements.
Although EU-hosting is important for AI platforms, it is only one part of the bigger picture.
The 4 Surfaces of EU Data Residency AI
AI data residency is not just about where the app is hosted. It also includes where prompts are processed, where enterprise data is indexed, how much context is retained, and what gets written into logs. That is why the strongest way to evaluate AI residency is through 4 surfaces: inference, retrieval, context, and logs.
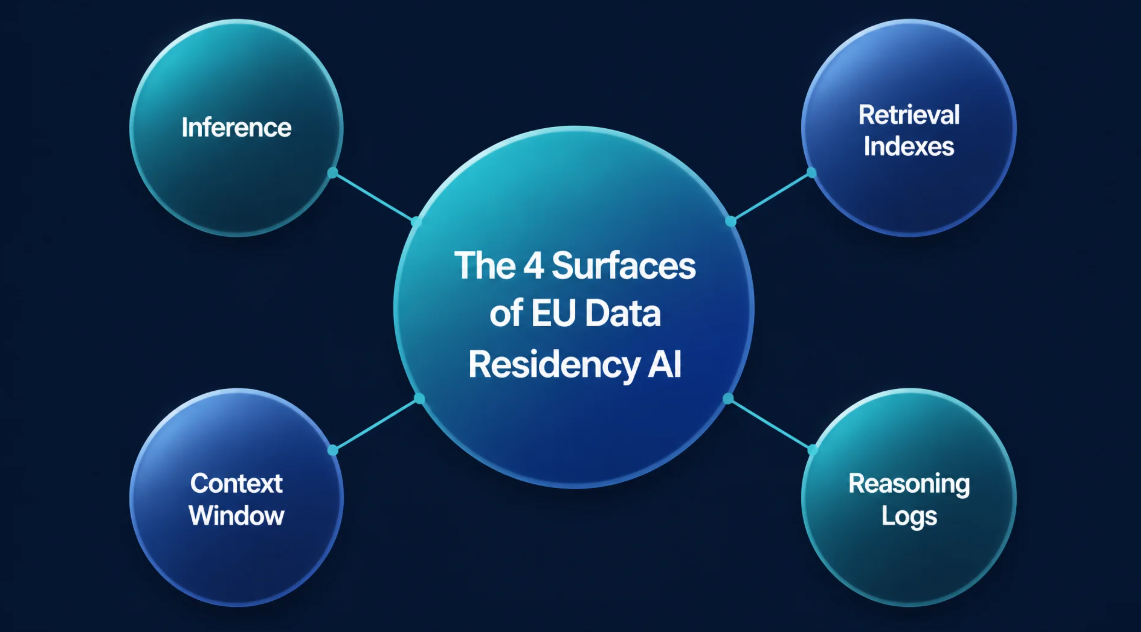
Layer 1: Inference
This is the moment when a user enters a prompt, the model processes it, and the output is generated. In other words, inference is where your request actually becomes an answer. If you are evaluating an AI platform for enterprise use, this is one of the first things you need to check. Interference can include internal documents, customer data, legal questions, strategy notes, or operational details. If the inference layer is unclear, your entire AI deployment becomes harder to govern. That is why inference should never be reduced to a marketing phrase like “hosted in Europe.” You need a clear answer on where requests are processed, how data flows during generation, and whether prompt data is retained after the response is produced.
Layer 2: Retrieval Indexes
The second surface is the retrieval indexes. If the AI can access your knowledge, you need to know where that knowledge is indexed. Many enterprise AI tools do more than generate answers from a prompt. They also connect to company data such as internal documents, wikis, support articles, PDFs, meeting notes, or cloud drives. To make that information searchable, the platform often creates indexes. This is where a lot of buyers miss the bigger picture. A vendor may say that its chat experience is EU-hosted, but if the retrieval layer stores indexed company data somewhere else, then the residency question is not fully answered. You need to know where those indexes live, where embeddings are stored, where synced content is processed, and whether connected sources stay within the intended region.
Warum ist das wichtig?
Because retrieval indexes often contain the structure of your company knowledge. They may not look like the original document, but they still represent enterprise data. If your AI assistant can search HR policies, customer support content, legal templates, or product documentation, then the retrieval layer becomes a major part of your compliance and governance review.
Layer 3: Context Window
The third surface is the context window. This is the layer that gives AI systems continuity. It includes the information that is carried into a session so the model can generate a more relevant answer. Depending on the platform, that can include recent conversation history, workspace instructions, memory, agent settings, attached files, and user-specific context.
Warum ist das wichtig?
Because context is what makes enterprise AI truly useful. It helps the system understand what your team is asking, what data it should rely on, and how it should respond. But at the same time, context can also include sensitive material that needs to be managed carefully. Therefore, you need to know how long conversation histories are stored, whether administrators can control retention, and whether memory is limited by workspace, user, or project.
Layer 4: Reasoning Logs
The last but not least surface is reasoning logs. Reasoning logs refer to the records created around how an AI request was handled. Depending on the platform, this can include usage metadata, tool traces, debugging records, workflow steps, timestamps, error logs, monitoring events, and other observability data. This surface is easy to overlook, but it is one of the most important ones.
Warum ist das wichtig?
Because even when a vendor limits prompt retention, operational logs may still capture meaningful information about how the system was used. For enterprise buyers, this affects auditability, incident response, security review, and internal governance. A platform may look strong at the interface level, but if its reasoning logs are vague, unrestricted, or poorly documented, security teams will notice. That is why mature enterprise AI vendors need to be clear not only about where answers are generated, but also about how the entire request lifecycle is monitored and recorded.
TextCortex AI: European Frontier Model Provider and Enterprise AI Solution
If you're looking for a European AI provider and enterprise AI tool platform that offers all EU data residency tiers, TextCortex is the solution for you. TextCortex is a platform that aims to meet the AI requirements of enterprises by offering frontier AI models to its users in an EU-hosted and GDPR-compliant manner. With TextCortex, you can use 24+ large language models via a single API, compliant with EU data residency. Furthermore, TextCortex provides monitoring, logging, and auditing to its users, allowing you to always keep track of your AI models. Let's take a closer look at the features of TextCortex.
EU-Hosted LLM Access
TextCortex allows users to utilize 30 different models via a single API, all EU-hosted and GDPR compliant. These models include frontier AI models like GPT-5.5, Claude Opus 4.7, and Gemini 3.1 Pro, as well as alternative and budget-friendly options such as KimiK2.6, GLM 5.2, and DeepSeek V4 Pro.
EU-Hosted Enterprise AI Experience
In addition to being an LLM provider, TextCortex also offers its users an EU-hosted and GDPR-compliant enterprise AI platform. With TextCortex, you can automate complex and repetitive workflows or enhance your knowledge management using a wide range of LLMs. You can build automation agents for specific tasks using the TextCortex AI agent framework. Furthermore, with our knowledge bases, you can integrate your internal databases with TextCortex to access the information you need in a conversational format or transform your raw data into useful outputs.
Häufig gestellte Fragen
What is EU data residency for AI?
It refers to where AI-related data is processed, stored, indexed, or logged across the AI stack.
Is EU hosting the same as AI sovereignty?
No. EU hosting is about location. Sovereignty also includes jurisdiction, governance, control, and operational independence.
What should enterprises check beyond inference location?
They should also verify retrieval, context, and logs.
Can an AI tool be GDPR-aligned if it uses US model providers?
This depends on architecture, contracts, safeguards, data flows, and governance controls. Buyers should verify the full processing chain.
.png)
.png)
.png)