.png)
La tecnología de inteligencia artificial ha evolucionado desde los chatbots hasta el uso de agentes de IA y la automatización. Antes se usaba solo en forma de chatbots con funciones como la búsqueda basada en bases de conocimiento, pero ahora la tecnología de IA se utiliza con diversas herramientas de automatización, para automatizar por completo tareas repetitivas y, sobre todo, en las empresas para ahorrar tiempo y mano de obra. Este cambio exige que los agentes de IA tomen precauciones contra un nuevo tipo de ataque: los ataques de inyección de comandos, que han ocupado el primer puesto en la lista OWASP Top 10 para aplicaciones LLM desde que se publicó por primera vez y siguen en lo más alto en la edición de 2025. Descubramos formas de prevenir los ataques de inyección de comandos.
TL; DR
A medida que los agentes de IA pasan de ser simples chatbots a convertirse en sistemas autónomos que manejan herramientas y flujos de trabajo reales, se convierten en objetivos principales de los ataques de inyección de prompts, unos trucos textuales que manipulan a los modelos para que filtren datos o tomen decisiones perjudiciales. Defenderse de ellos implica aplicar controles por capas: depurar las entradas, restringir privilegios, mantener a las personas al tanto de las acciones críticas, filtrar las salidas y supervisar las anomalías en tiempo real. Combina todo eso con una autorización estricta de herramientas, el cumplimiento normativo y registros de auditoría detallados. Si necesitas una plataforma lista para la empresa que combine la automatización de IA con las garantías de SOC 2, ISO 27001 y el RGPD, TextCortex una infraestructura segura diseñada precisamente para eso.
¿Qué es la inyección inmediata?
La inyección de prompts es un método de ataque textual que usan los atacantes para manipular el comportamiento y los resultados de un modelo de lenguaje a gran escala. Los ataques de inyección de prompts conllevan riesgos como el robo de datos, el acceso no autorizado, la generación de contenido perjudicial, el incumplimiento de las directrices y la toma de decisiones erróneas. Consiste en introducir entradas específicas y alterar los resultados del modelo para manipularlo. La inyección de prompts tiene dos variantes: directa e indirecta.
Inyección directa
La inyección directa de comandos se produce en plataformas en las que el atacante interactúa directamente con el modelo de lenguaje grande. Por ejemplo, los chats que permiten interactuar con el modelo de lenguaje grande son un método de ataque ideal para la inyección directa de comandos. Como este método de ataque es directo, es relativamente fácil de bloquear y contrarrestar.
Inyección indirecta de comandos
La inyección indirecta de comandos se produce en situaciones en las que los modelos de lenguaje a gran escala (LLM) pueden interactuar con recursos externos. Por ejemplo, cuando los LLM interactúan con sitios web o bases de datos, o conceden permisos para subir archivos, existe el riesgo de inyección indirecta de comandos. Esta amenaza está creciendo rápidamente: según un análisis de Palo Alto Networks, los escaneos de contenido web realizados por Google detectaron un aumento del 32 % en el contenido malicioso diseñado para la inyección indirecta de comandos entre noviembre de 2025 y febrero de 2026.
¿Cómo evitar que se forme una protuberancia en la zona de la inyección?
Hay varias medidas que puedes tomar para evitar una inyección prematura. Vamos a verlas paso a paso.
1. Sanización de entradas
La primera forma de prevenir la inyección de comandos es configurar qué entradas aceptará tu modelo de lenguaje grande y cuáles se marcarán como maliciosas y no se procesarán. Por ejemplo, debes enseñar a tu modelo a no procesar entradas que le obliguen a ignorar comandos anteriores y precauciones durante los juegos de rol. Las entradas que usan demasiada puntuación también suponen un riesgo de alterar el comportamiento del modelo. La primera medida y el primer escudo que debes adoptar es restringir el efecto que tendrán las entradas sin procesar en tu modelo.
2. Minimización de privilegios
Un agente de IA solo debería tener acceso a la información que necesita y que va a utilizar. De esta forma, en caso de que se produzca una inyección de comandos, el agente de IA podrá evitar causar daños graves. El informe «Cost of a Data Breach 2025» de IBM reveló que el 97 % de las organizaciones que sufrieron brechas relacionadas con la IA carecían de controles de acceso adecuados, lo que refuerza la idea de que un agente de IA que solo usas para leer tus correos electrónicos no debería necesitar también acceso para escribir y enviar correos, ni para transferir tus correos a otro documento y enviarlos a otro medio.
3. Intervención humana
Aunque los agentes de IA pueden automatizar la mayoría de las tareas, usarlos para una automatización total es peligroso, sobre todo en tareas críticas. Por eso, en áreas críticas como el envío de dinero, la emisión de facturas, el envío de correos electrónicos y los procesos de pago, debes evitar que el agente de IA tome la decisión final y asegurarte de que sea un humano quien la tome. De esta forma, en caso de un ataque de inyección de comandos, el agente de IA podría someter los procesos críticos al control humano antes de que se completen.
4. Filtrado de salida
La inyección de prompts consiste en manipular la salida de los agentes de IA o los grandes modelos de lenguaje a través de la entrada. Por lo tanto, puedes evitar la mayoría de los ataques de inyección de prompts sin que se produzcan daños filtrando la salida del agente de IA o del gran modelo de lenguaje.
5. Detección de inyección de comandos en tiempo real
Los clasificadores especializados y los motores de reconocimiento de patrones analizan constantemente las entradas y salidas, identificando instrucciones peligrosas, posibles ataques y estructuras maliciosas. Cuando se detecta cualquier ataque de inyección de comandos, se bloquea la generación de la salida. Los permisos y las acciones del agente de IA se restringen, lo que evita el posible ataque de inyección de comandos. Esta capa de defensa es fundamental: los estudios de seguridad muestran que el 73 % de los sistemas de IA evaluados en auditorías de seguridad están expuestos a vulnerabilidades de inyección de comandos, pero los métodos de detección actuales solo detectan el 23 % de los ataques sofisticados sin un escaneo en tiempo real específico.
6. Supervisión del comportamiento y detección de anomalías
Los sistemas de supervisión del comportamiento y detección de anomalías analizan fuentes de datos inusuales; detectan cualquier solicitud anómala y te avisan. Esto te permite supervisar simultáneamente tu agente de IA o tu modelo de lenguaje a gran escala y detectar directamente posibles ataques de inyección de solicitudes, como cuando un agente de IA intenta de repente realizar 500 API .
7. Autorización para el uso de herramientas
Los agentes de IA tienen cada día acceso a más aplicaciones y herramientas de terceros. Esto hace que el uso indebido de herramientas sin la debida autorización sea un blanco perfecto para los ataques de inyección de comandos. Al autorizar qué herramientas pueden usar cada usuario y bajo qué parámetros, puedes proteger a tu agente de IA de los ataques de inyección de comandos y evitar que se convierta en un bot que filtre datos. Si tu plataforma de agentes de IA te permite autorizar a los usuarios y gestionar sus permisos, ya vas un paso por delante.
8. Armonización normativa
Las normativas internacionales garantizan que los agentes de IA estén protegidos no solo contra la generación de contenido malicioso, sino también contra otros riesgos, como los ataques de inyección de comandos en agentes de IA. En particular, el marco de seguridad para agentes de IA del NIST exige una revisión con intervención humana en las operaciones que impliquen datos personales, transacciones que superen los umbrales definidos, acciones irreversibles como la eliminación de datos y cualquier acceso a nuevos sistemas externos. Debes asegurarte de que el agente de IA o la plataforma de agentes de IA que utilizas cumple con las normativas globales y cuenta con la certificación correspondiente. Esto garantiza que tu agente de IA funcione de forma más segura y sea más resistente a los ataques de inyección de comandos.

9. Auditoría y registro
Asegúrate de auditar y registrar cada acción y decisión del agente de IA. Esto te permite detectar comportamientos anómalos o identificar en qué momentos el agente de IA cometió un error. Tras cualquier ataque de inyección de comandos, auditar y revisar los registros te ayudará a tomar medidas preventivas contra ataques similares.
TextCortex: Infraestructura de agentes de IA segura y protegida
Si quieres que tus agentes de IA y los modelos de IA que integras en tu empresa sean eficaces y fiables, TextCortex la solución que necesitas. TextCortex sus usuarios una experiencia de IA segura y protegida, además de acceso a las últimas funciones de automatización e IA. Entre las funciones principales que ofrece TextCortex :
- Agentes de IA para la automatización
- Bases de conocimiento
- Habilidades
- Navegador Extension
- Conectores
- Sin fisuras Integrations
- Creador de agentes de IA
- Varias bibliotecas de modelos de lenguaje grande (LLM), entre ellas Claude Opus 4.7 y GPT-5.5
- Generadores de imágenes múltiples
- Acceso web
Además, TextCortex todas estas funciones con una seguridad de última generación.
TextCortex : Seguridad y protección con TextCortex
TextCortex diversas medidas de seguridad para proteger los datos confidenciales de sus usuarios. Puedes acceder a todos los programas e información sobre seguridad TextCortex a través de este enlace. Las primeras soluciones de seguridad de IA para empresas TextCortex son sus certificaciones y su cumplimiento normativo. Además de cumplir con la normativa de la Ley de IA de la UE y el RGPD, TextCortex las certificaciones SOC 2 Tipo I, SOC 2 Tipo II e ISO 27001.
Políticas
TextCortex políticas en cuatro áreas diferentes para que los usuarios disfruten de una experiencia segura con la IA:
- Seguridad de las aplicaciones
- Seguridad y privacidad de los datos
- Seguridad de las infraestructuras
- Operaciones de seguridad

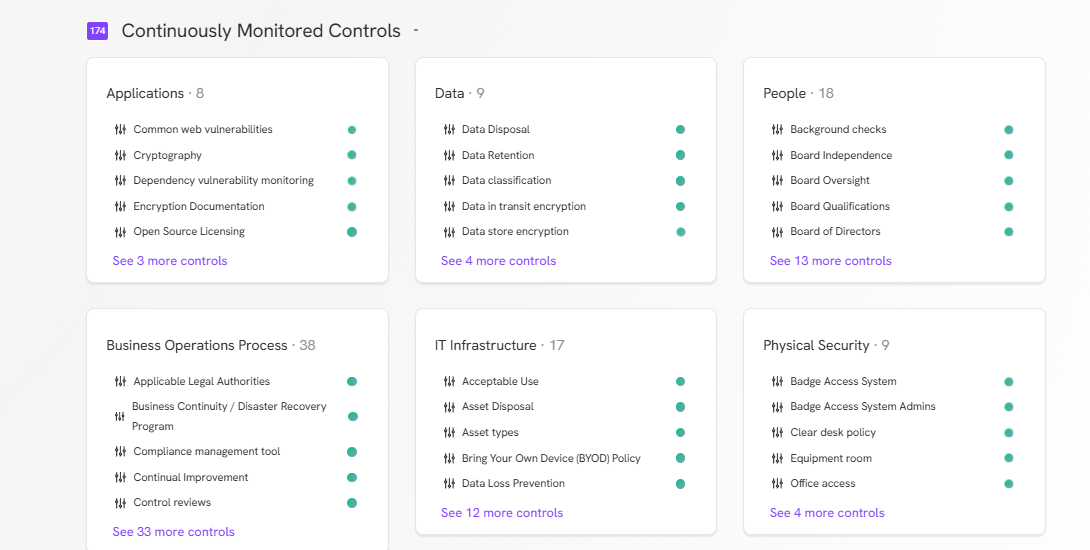
Controles supervisados de forma continua
Antes de integrar TextCortex tu empresa, debes saber que te permite supervisar de forma continua una amplia gama de controles. Con TextCortex, puedes supervisar controles en las siguientes categorías:
- Aplicaciones
- Datos
- Gente
- Proceso operativo empresarial
- Infraestructura de TI
- Seguridad física
- Infraestructura en la nube
- Identidad y control de acceso
- Privacidad
- Clientes
- Seguimiento
- Proceso de entrega del producto
- Proveedores

Preguntas frecuentes
¿Qué es exactamente la inyección rápida y por qué debería importarle a mi empresa?
La inyección de comandos consiste en que un atacante introduce texto malicioso en el flujo de entrada de un agente de IA para engañar al modelo y que este ignore sus instrucciones, filtre datos o realice acciones no autorizadas. No se trata de un riesgo teórico: Snyk descubrió que el 36 % de las habilidades de ClawHub contienen inyecciones de comandos detectables, y las empresas ya están encontrando vulnerabilidades CVE reales relacionadas con la IA agentiva.
¿Cuál es la diferencia entre la inyección directa y la indirecta?
La inyección directa de comandos se produce cuando un atacante escribe un comando malicioso directamente en la interfaz de chat, intentando anular la línea de comandos del sistema en ese mismo momento. La inyección indirecta de comandos es más sutil: el atacante oculta instrucciones maliciosas dentro de un recurso externo que utiliza el agente, como una página web, un PDF o una entrada de una base de datos.
¿Basta con la sanitización de entradas para evitar la inyección de comandos?
La sanitización de entradas es tu primer escudo, pero por sí sola no es una fortaleza. Funciona detectando y bloqueando patrones como prefijos de juegos de rol, frases del tipo «ignora las instrucciones anteriores» o un uso excesivo de signos de puntuación que intenta traspasar los límites de los delimitadores. El problema es que los atacantes siempre encuentran nuevas formas de ocultar sus entradas. La sanitización te da tiempo y detecta los intentos más obvios, pero para que sea realmente eficaz hay que combinarla con límites de privilegios, filtrado de salida y supervisión.
¿Hay alguna forma de detectar la inyección de comandos en tiempo real?
Sí. Los clasificadores especializados y los motores de reconocimiento de patrones pueden analizar continuamente tanto las solicitudes entrantes como las respuestas salientes, buscando estructuras adversarias como la anulación de instrucciones o la ruptura de delimitadores. Cuando se detecta una firma de amenaza, el sistema puede bloquear la solicitud, restringir los permisos del agente o desviar el tráfico a una alternativa más segura. Microsoft y otras plataformas ofrecen protectores de solicitudes y pasarelas de IA que actúan como esta capa de control en tiempo real.
¿Realmente exigen las normativas internacionales que se implementen medidas de defensa contra inyecciones maliciosas?
Normativas como la Ley de IA de la UE, el Marco de Gestión de Riesgos de IA del NIST y la norma ISO/IEC 42001 exigen cada vez más transparencia, supervisión humana y gestión de riesgos para los sistemas de IA. Aunque ninguna de ellas utiliza literalmente la expresión «inyección de prompts», el requisito de evitar la manipulación no autorizada, la fuga de datos y los resultados perjudiciales se corresponde directamente con la mitigación de la inyección de prompts.
.png)
.png)
.png)